“Are potatoes ‘badder’ than usual in the UK atm?” This was the question posed by a reddit user last week. Despite the scare quotes, this use of the word ‘badder’ was met with general mockery (as well as some genuine attempts to answer the question: the wet weather has caused poor growing conditions for root veg this year, if you were wondering). Yet the intended meaning is completely clear to English speakers; more so than if it had been phrased ‘are potatoes worse than usual?’.
In fact, ‘badder’ has seen a big increase in use since the mid 20th century (although it’s been around for a long time, and was even used by Chaucer). Google books offers numerous titles from recent years such as Bigger and badder: a billionaire romance (2016), How to be a badder bitch (2018) and the Bad guys even badder box (2019). What these titles have in common is that ‘bad’ is used with a special meaning as part of a set phrase. ‘Bad guy’ evokes a stock villain from a story, not just any old guy who happens to be bad. A ‘bad bitch’ is a tough, empowered woman. Thus a ‘badder guy’ is even more villainous, and a ‘badder bitch’ is even cooler and tougher. ‘Can you imagine a worse bitch than Helen?’ makes it crystal clear that the speaker doesn’t like Helen, but ‘can you imagine a badder bitch than Helen?’ implies admiration instead.
These are examples of what linguists call lexicalisation. ‘Bad guy’ and ‘bad bitch’ have become set phrases whose meaning is more than just the sum of their individual parts. In other words, the meaning of ‘bad guy’ is not just the meaning of ‘bad’ + ‘guy’, and would have to be listed as a separate entry in a dictionary. In a sense, it behaves as a single word (which is also betrayed by its special stress pattern: a bad guy is a guy who is bad, while a bad guy is a villain). This is even clearer for ‘bad bitch’: both bitch and bad have strongly negative connotations, but bad bitch is positive.
The coinage of ‘badder bitch’ reveals a change that has already happened under the surface. Two words have become one phrase, with its own unpredictable meaning. Bad and worse are forms of the same lexeme, in the sense that they’d be listed under the same dictionary entry: they are members of the same paradigm. ‘Badder bitch’ shows that changes in meaning can happen to individual forms in the paradigm, rather than lexemes, otherwise ‘worse bitch’ would automatically take on the meaning of ‘bad bitch’. Bad in the newly lexicalised bad bitch starts off its life without any comparative form, so you’ve got to make up something new if you want to use one.
Something similar can be seen in examples like straight or wrought, which started off life as past participles of the verbs stretch and work. Straight in a sentence like ‘I have straight the string’ was regularised to stretched, and wrought to worked. But the forms straight and wrought were left behind in usages like ‘the straight string’ or ‘the wrought iron’, revealing that they had become lexicalised as adjectives in their own right.
Back to badder potatoes. Bad in the context ‘a bad potato/apple/egg (etc.)’ has a special sense of ‘rotten’ that is somewhat lexicalised, hence ‘badder potatoes’ are more rotten, while ‘worse potatoes’ could be worse in any number of ways. Either that, or potatoes are becoming meaner and more villainous as a result of the miserable weather, which frankly I can relate to. Let’s remain vigilant, just in case.
A villainous potato coming to get you, courtesy of https://hotpot.ai/art-generator
There are plans and then there are fieldwork plans. Sometimes everything does go without a hitch. This is not one of those times. The plan was to visit four different communities in Vanuatu who I had been working with over the last few years. I was there to donate the vernacular literacy materials we had created as part of our project and to run a teachers’ survey to find out what other resources and training they needed to teach the local languages in early years education.
The printers had sent the books a month earlier to Vanuatu – 14 large boxes weighing 15kg each. But by the time I arrived in Vanuatu the books had still not arrived. I checked the tracking number on the website and the books had been ping-ponged around different locations – India, China, Japan, Sydney, back to China and then Sydney again. Apparently the international shipping company tasked with the job couldn’t find Vanuatu on the map!
Vernacular literacy materials made for Merei, North Ambrym, Lewo and Vatlongos languages
A few days later and still empty-handed with the books having not arrived, I was on the short plane ride to Santo Island followed by a three and a half hour tediously slow and bumpy truck drive to Agoru village, the largest village where the Merei language is spoken. Merei has just over 1000 speakers in a collection of villages between the Labe and Jordan rivers in northern Santo. There had been lots of rain, and the deep potholes in the unsealed road had filled with water. As we descended the steep muddy hill to cross the ford at the Labe river, I could feel the 4 wheel drive start to lose grip and ski down the slope.
Melikio and Me at the ford over the Labe river
Luckily, we made it in one piece! I stayed the night at Adam’s house, a Bible translator from Brisbane, who had been living there for almost twenty years. I met one of my good friends from my last visit – Melkio, and we went for a few shells of kava. Kava is the name of the plant piper methysticum, a type of pepper plant and the national drink of Vanuatu. The roots are peeled and then ground up and mixed with water to create a mildly intoxicating drink that relaxes your whole body. The next morning, we were off again to Vusvogo village – to the main event – Merei Day! This is a celebration to encourage the use of the Merei language and preserve their cultural heritage. I was hoping that lots of teachers from the different schools would be there so I could give them the digital copies of the literacy materials and conduct the interviews.
The journey itself was an adventure that I wasn’t properly prepared for. The last time I visited, the truck dropped me off close by, but this time the road was so muddy that the truck couldn’t get through. I hopped into the flat bed of the truck along with Melkio, Ishmael and Norman (two of the main bible translators who work with Adam), their wives, children and a few others. We were dropped off at the ford. We walked along the bank. It was easy going for the first few hundred metres before the track turned into a quagmire. The horse riders churn up the track, so the mud comes half-way up your shins. My flip-flops were not up to the job, and I had to go drae-leg ‘bare-footed (literally, dry-leg in Bislama, the national creole language of Vanuatu). It was slow going, and I made new friends in the best way possible, by humiliating myself – slipping and sliding all over the place. We got to the crossing point of the Labe river, by a small village. The current was strong, and the water came up to my chin – so we all had to swim across. We put our bags (and the babies!) in a large metal dish used for washing clothes, which three of the men carefully floated across the river. More mud and another, much easier river crossing, and we were at Vusvogo – after a three-hour mud-filled hike!
Swimming across the Labe river
The event didn’t start until the next day. We piled into the nakamal, a low, long single-room traditional meeting house. One half for the men and the other half for the women. This is where we would drink kava, eat, sleep, and celebrate. My bed for the night was a woven pandanus mat on the hard mud floor. We drank more kava before I fell asleep listening to the women chat next to me and the obligatory hocking and spitting noise coming from the men drinking kava. The fire was kept stoked all night long, while a piglet poked its way in to the nakamal and was snouting around.
My bed for the weekend
Breakfast was leftovers from the night before, stewed beef and rice served on a large pudding leaf (a bit like a banana leaf). I wandered over to the church and found Adam, Melkio, Norman, Ishmael, and Father Manuel. We drank sweet lemon leaf tea and we talked about different ways of promoting the use of local language in schools. I joined Adam at the back of the church. We both had the same idea, seeking out a little bit of comfort by leaning against the posts of the church. The Anglican sermon was all in Merei and a written version had been produced so I could at least follow the words, but not their meaning! A few hours later, we formed a procession back to the nakamal. Everyone was wearing their traditional clothes – loin-cloths for the men and leaf covering for the women.
Planting of the ceremonial cycad palm outside the nakamal to mark the occasion
Back at the nakamal everyone was giving speeches, The chief, the councillor, Adam and even I was asked to give an impromptu speech! I talked about my work with the community, the literacy materials I had made and the importance of keeping the language alive. Then the main event started – a smorgasbord of traditional food – taro, a starchy root crop, cooked in a myriad of ways. There was even traditional salt made from the ash of a particular tree. Every minute my name was called out Mike kam tastem! ‘Mike, come and taste!’. There was so much enthusiasm and pride in sharing their traditions. The main dish was taro nalot. Roasted taro was pounded by big sticks on a large flat wooden dish. The rhythmic pounding made the event even more theatrical as different beats rang out.
The pounded taro nalot
Then came a display of string figures, cats-cradle like figures made out of twine, followed by traditional dancing and games outside. The large buttress of a nakatambol ‘dragon-plum tree’ had been cut and used to cover a hole. Men in the centre beat the bass-drum, while singing, and other men and women danced in circles around them.
Making string-figures in the nakamalBeating the nakatambol bass-drum
I found time to interview the teachers and share the digital copies of the books. They were all excited to use them and couldn’t wait for the hard copies. They had no literacy materials in their language before, except for an ABC poster. Hopefully, our materials will help start the move towards vernacular education in this community. As the sun set, I joined the men and drank kava until the milky way was clear in the sky. I fell asleep on the pandanus mat, only woken by that cheeky piglet snuffling about again.
Children playing traditiona games outside of the nakamal
The rest of my trip to Vanuatu went quite well. I managed to visit another two communities on the neighbouring island of Ambrym. But I got stuck in South-East Ambrym due to a flight cancellation and missed out on going to the fourth community on Epi. Back in the capital city, Port Vila, I was interviewed on local radio about my work and took part in a panel discussion at the national University about vernacular language education, as well as giving two talks at the Vanuatu Languages Conference. I also organised for three local language speakers from North Ambyrm, Vatlongos and Lewo attend a language documentation training session run by the Endangered Languages Documentation Programme in an effort to move towards more sustainable and community-driven practices in language docuemtation by capacity building with local experts. A busy, and mostly successful trip.
By the end of my six-week trip the books had finally arrived, only to be held up in customs while I organised a customs exemption from the Ministry of Education. And as I write this, three months after my trip, and four and a half months after the books started their journey, they are on their final leg of their journey – on cargo ships to Santo, Ambrym and Epi. It would have been wonderful to have handed out the books to each community myself, but things never quite go to plan with fieldwork.
I wish to thank Adam Pike, Melkio Wulmele, Willie Salong, Yanick Tekon, Loui and Gari Maki, Simeon and Madlen Ben, Helen Tamtam, Robert Early, Eleanor Ridge, Henline Mala and Andrea Bryant for all their help with the fieldtrip, the literacy materials, and their hospitality. Finally, a thank you to our funders, the ESRC and the University of Surrey’s Impact Acceleration Account for making our work possible.
When you want to look up a word, how do you go about it? The dictionary is organised by the first letter of the word, so that is what you consider first. And when you want to compare languages, what is the first thing to catch your eye? Again, the first sound. Thus, when looking at a set of words like English fish, father, full, Latin piscis, pater, plenus and Scottish Gaelic iasg, athair, làn, the fact that f- in English corresponds to p- in Latin and zero in Scottish Gaelic spring immediately to our attention, reading as we do from left to right.
Thus, we might presume that the beginning of a word is somehow especially stable, and that sounds which appear at the beginning of a word are a good first indicator of etymology. However, in fact the beginning of a word is not so immutable as you might suppose. Famously, Celtic languages have initial consonant mutations, which alters the initial consonant of a word in regular ways depending on grammatical context. So in Welsh, while ‘Wales’ is Cymru, ‘Welcome to Wales’ is Croeso i Gymru, ‘in Wales’ is yng Nghymru and ‘England and Wales’ is Lloegr a Chymru. This is interesting enough, but not the only way that the start of a word may be altered in languages. Indeed, we don’t even have to leave English to find examples of a different phenomenon that can take place in the history of an individual word.
Let us take a word like adder (the snake specifically, not someone that does addition!). We can look for cognates in closely-related languages, but we are immediately presented with a problem: German Natter, Frisian njirre and Icelandic naðra all seem like they should be related (all being words for ‘snake’), but what’s with this n- at the beginning of the word? Things only get more confusing when we notice words like Latin natrix ‘watersnake’, Welsh neidr or Scottish Gaelic nathair, all again showing an n-. Finally, when we look at Old English we find that the word there is næddre! What’s going on? We know that in general English n- doesn’t do anything particularly strange and it certainly doesn’t just disappear from the beginnings of words, as evidenced by numerous forms like name, night, nest, new, and nine which have had an n- since Proto-Indo-European!
The answer lies in a phenomenon that linguists call ‘rebracketing’. This is a fairly straightforward notion; linguists already make use of brackets to show the internal structure of phrases, thus any change in the structure of the phrase is notated by a change in the arrangement of the brackets. (It will be noted that some authors, including the Oxford English Dictionary, use the term metanalysis instead, but the meaning is the same.)
In the case of adder, the confusion comes from the indefinite article, which in English is a before words beginning with a consonant and an before words beginning with a vowel. Thus, if a word begins with an n-, this can find itself being rebracketed onto the indefinite article: thus [a [nadder]] becomes [a-n [adder]]. And this isn’t the only word where this has happened in English either: thus [a [napron]] (from French napperon) became [a-n [apron]]. On the flipside, the opposite is also found, where the -n from the indefinite article finds itself attached to the front of a word that originally began with a vowel, e.g. [an [ewt]] → [a [n-ewt]] or [an [ekename]] → [a [n-ickname]].
An ewt!
Some of these forms have since become the predominant forms of their respective words, but such is not always the case. For example, uncle derives from a French word oncle, ultimately from Latin avunculus. However, those who are familiar with their Shakespeare will remember the Fool in King Lear, who refers to the title character as ‘nuncle’. Here the reanalysis, rather than from the indefinite article, seems to have been on the basis of possessive pronouns mine and thine, which are particularly frequently used with kind terms: thus [mine [uncle]] becomes [my [nuncle]]. Yet, unlike with the other examples, this has not stuck around, perhaps because the other possessive pronouns (his, her, our, your, their) which would not have motivated this reanalysis; thus the original uncle stuck around and was able to reassert itself.
Nor is English alone in exhibiting these kinds of change. In the adder~nadder case, the same reanalysis has also taken place in Dutch and Low German, also spelt adder in both cases. Similarly, Arabic nāranj was borrowed into Spanish as Naranja, but this underwent rebracketing when it was borrowed into Italian as arancia, and it was from there that the word spread to the rest of Europe, including English orange.
French provides us with an especially interesting example of layered reanalyses in a single word. In Old French, unicorne was reanalysed as beginning with the indefinite article (which is in a sense not incorrect: the literal meaning of the word is ‘one-horn’ and ‘one’ is the source of the French indefinite article, as well as indefinite articles in general cross-linguistically). This left a form icorne, which would contract with the definite article, giving l’icorne ‘the unicorn’. However, at some point, this contracted form with the article came to be reanalysed as the base of the noun itself, with the result that licorne is now simply the French for ‘unicorn’, leading to constructions such as la licorne ‘the unicorn’ where a historical definite article appears ‘doubled up’!
Some of the most complex cases of rebracketing can be found in Scottish Gaelic. Here we have a number of potential sources of rebracketing, both because the definite article changes depending on the following noun and because of the interaction of the definite article and the mutation system.
Firstly, with vowel-initial masculine noun the definite article prefixes a t- e.g. eun ‘bird’ but an t-eun ‘the bird’. Unsurprisingly, based on the examples we have seen above, this prefixed t- has in many cases become attached to the noun. Interestingly this is particularly common in loanwords from Old Norse, such as talla ‘hall’ from hǫll, tòb ‘small bay’ from hóp (òb is also common) and tolm ‘small islet’ from holmr, as well as other loans such as taigeis ‘haggis’ and tobha ‘hoe’ from English.
In a similar vein, one of the components of consonant mutation is Scottish Gaelic is that an f sound disappears (though is still written as fh). As a result, a larger number of words that began with vowels in Old Irish have acquired an f- in Scottish Gaelic, e.g. áinne ‘ring’, uar ‘cold’ and íaru ‘squirrel’ have become fáinne, fuar and feòrag respectively, as if an áinne uar ‘the cold ring’ was really an fháinne fhuar. Many of the words have undergone the same kinds of changes in Irish and Manx, though not all languages agree on which (e.g. Irish also has fáinne and fuar but iora respectively).
And, as in English, words that begin with n- can find this consonant being rebracketed as part of the article an. However, once this n- has been rebracketed, this now vowel-initial word can undergo the same kinds of mutation-based reshaping as an originally vowel initial word. Perhaps the most extreme example of this is ‘nettle’, which was nenaid in Old Irish, but in Scottish Gaelic can be (depending on who you ask) any of neanntag, eanntag (with the n- rebracketed away), feanntag (with the f- appended by lenition reversal) and deanntag (where the d- is apparently a hypercorrective reversal of a process of nasalisation in the Northwestern dialects)!
neanntag, eanntag, feanntag or deanntag?
So, when searching around for a word in a dictionary or an old text, be cautious; simply looking for the first consonant to give you a clue might be misleading when taken out of context. Furthermore, instances like these make clear that language is primarily a spoken phenomenon and the kinds of changes that we see reflect that: while in a written text the different between a newt and an ewt is obvious, in spoken language the question of where one word ends and the nexts begins is not so straightforward as a casual glance at a dictionary might suggest. Perhaps this should then make us ponder further how much written language is a direct reflection of spoken language versus being at least partially arbitrary choices made by the writers.
Last month, the Guildford Shakespeare Company put on a production of Richard II, a fascinating tale of political strife and the perils of having a leader lacking in competence when the country is in crisis. Sound familiar? In any case, this got me thinking about the name Richard and its many etymological links.
First with the name Richard. It’s borrowed from French, but it didn’t start there. In fact it is one of a number of French words that was borrowed from Germanic, deriving from Frankish *Rīkahard, meaning ‘hard/brave king’. This also gives modern German Richard and through the travels of the Goths and Vandals also made its way into Spanish as Ricardo and Italian as Riccardo. The first part of this name, the *rīk- ‘ruler’ part, in other derivations also gives words like German Reich and Dutch rijk, both meaning ‘empire’ or ‘kingdom’, which in English is also found as the ‘domain, kingdom’ suffix -ry, as in Jewry ‘the Kingdom of the Jews’. As different derivation again gives us English rich, something you’d rather expect a king to be. As a component of names it is ubiquitous in Germanic, such as in Old English Godric ‘God(ly) king’, Wulfric ‘Wolf-king’ and Theodric ‘King of the people’. This last one turns up in German as Dietrich and, again courtesy of the Franks, through French Thierry comes into English as Terry (see also my previous post on the Germans for more on this Theod-).
But it is not only Germanic languages that have this root. Indeed, some form of it crops up across the Indo-European language family, usually meaning something like ‘king’ or ‘ruler’. In Celtic (from which Germanic likely borrowed the rīk- words) we find e.g. rí in Irish and rhi in Welsh, both meaning king. In Gaulish, rulers such as Vercingetorix and Ambiorix had an earlier form –rix it as part of their name, and in a reduced form we find the same in the Welsh surname Tudor, originally meaning ‘ruler of the people’ and thus cognate with Theodric/Dietrich/Terry.
In Latin too we find rēx, again meaning ‘king’ or ‘ruler’. This form survives as such in many modern Romance languages, for example Spanish rey and French roi. We also get two separate adjectives in English: regal from Latin and royal from French. Further afield, we find this word cropping up as far away as India, in the form of Sanskrit rāja, once again a ‘king’ word, as well as rāṣṭrá, a ‘kingdom’.
All of these forms can be traced back to a form in Proto-Indo-European (the reconstructed ancestor of all of these languages), which we represent as *h3rḗǵs. In the terminology of Indo-European studies this is an ‘athematic root noun’, meaning a short root without additional derivational suffixes onto which inflectional endings such as the nominative singular *-s are suffixed directly, rather than having an additional ‘theme vowel’ *-o inbetween. As with many such forms in Proto-Indo-European, when we isolate the root itself, *h3reg-, which probably meant something like ‘stretch out the arm, direct’, we can find even more related derivations.
Adding a thematic vowel *-e/o- we get a verb which shows up in Latin as regō ‘rule, govern, direct’, along with an array of derived nouns which we have inn English. We have the agent noun rector, the instrument noun rule (from a French reflex of Latin rēgula) and the abstract noun regimen. Additionally, we have prefixed verbs such as dīrigō,ērigō and corrigō, which through their respective supine forms dīrēctum, ērēctum and corrēctum give us English ‘direct’, ‘erect’ and ‘correct’ respectively.
Germanic, meanwhile, provides us with a different set of reflexes of this verb. While we have already seen the rich set relating to wealth and kingship, the ‘straighten’ meaning of *h3reg- results in other interesting links. We have the (originally separate) verb and noun rake, a device for making straight lines, and the former participle right, originally meaning ‘straightened, directed’. Then we have reckon, perhaps a natural extension of the metaphor of lining things up in order to count them. Finally, from a causative ‘make straighten up’ we have reach (as if ‘straightening out one’s arm’).
This here is the greatest joy of etymology for me; by untangling these webs of relationships, we can show how so much of our vocabulary results from variations upon a common root. It reminds us of the continual creativity involved in using language and, by extension, the creativity of language users, i.e., humans.
Surrey Morphology Group, despite being a relatively small research group, nevertheless conducts linguistic fieldwork on all (inhabited) continents. Countries where members have worked over the years include Australia, Bulgaria, Canada, Colombia, Kenya, Mexico, Namibia, Nepal, Nigeria, Russia, Serbia, and Vanuatu. Fieldwork in every region has its peculiarities, not necessarily connected to the linguistic properties of the language(s) studied, and it is the peculiarities of one such region which I would like to discuss today.
My personal fieldwork experience has involved several different regions of Russia, in the republics of Daghestan, Mari-El, Komi and Khakassia. Each of these regions has been fascinating in its own way, but Daghestan takes the lion’s share of the fieldwork I do. It is a mountainous region in the south of Russia stretching from the Caspian Sea to the Caucasus. It has borders with Azerbaijan and Georgia to the south, and within the Russian Federation it is next door to Chechnya. Medieval geographers described the Caucasus as “a mountain of tongues”, and with good reason. There are over forty languages spoken in this relatively small territory (just 50,300 sq km), and most of the linguistic diversity lies within an even smaller mountainous region in the south of Daghestan, involving languages of the indigenous Nakh-Daghestanian family.
I wrote before about the linguistic interest of the language I have worked with the most, Archi (in many respects a typical representative of the family), but today I want to talk about social and cultural aspects of the work.
Culturally, Daghestan is a relatively homogeneous region; traditionally people lived in small villages, bred sheep and grew sturdy grains like rye and barley. Before the 20th century, many villages were organised as follows: there was one central village where people got together during summer months while the sheep were in the alpine pastures and did not need shelter during the night, and in winter months the people would go to smaller hamlets where the sheep (split into smaller groups) were kept in the houses or in underground sheepfolds made in the caves. The name for these winter sheepfolds is the same across several Daghestanian languages, so we can safely assume this was common practice for a long time.
Daghestanian shepherding
After the Revolution of 1917 and the creation of the Soviet Union, many people got the opportunity to drive the sheep to regions with a milder climate near the Caspian Sea, and these shepherding practices ceased to exist. The smaller hamlets either disappeared or grew into proper villages, and in the latter case developed some dialectal differences. The people like to notice those differences but at the same time they still often perceive the conglomerate of the central village and the “hamlets” (which in some cases are even larger than the central village) as a single village.
Besides sheep breeding, Daghestanian people grew grain, and traditionally they would roast grains and make flour out of them. That flour can be mixed with water and then eaten directly, and in some villages they still make this “shepherd’s food” (they call it “old time instant noodles”). There were also many traditional crafts, among which are the silver products of Kubachi, wood inlaid with silver from Untsukul, Lezgian knitted slippers and earthenware from Balkhar.
From a sociolinguistic point of view, the Daghestanian languages were in a much better state during the 20C than many other smaller languages of Russia. Although only a handful of Daghestanian languages were recognised by the state and therefore taught at school, children in smaller language communities remained monolingual until well into their teens. Most Daghestanian people belonging to smaller language groups also speak the language of a larger Daghestanian neighbour (such as Avar, Dargwa or Lezgian) and one national language, whether Russian, Azeri or Georgian, although in the last 50 years Russian has been steadily coming to replace the others. The first thing that strikes a linguist who comes to Daghestan (especially if that linguist has experience of working with small languages in other parts of the Russian Federation) is how proud the people are of their languages, how ready they are to share them, how much delight they take in their complexity. Indeed, since they all speak at least one other language, they can well see that their languages are more complex, at least phonetically (for example, Archi has 70 consonants).
Some places in Daghestan have kept their traditional ways better than others: thus, in 2004, when I first came to Archi, I was really fascinated to see many women wearing traditional clothes and jewellery not only on special occasions but every day.
Living in people’s houses, I could see that they used traditional cots for babies and had retained most of the old practices connected with childbirth. For example, right before having her first baby, the woman goes to her mother’s house and stays there for the first 40 days of the baby’s life, being completely looked after (very often she just stays in bed). After 40 days, she moves back to her and her husband’s house in a very colourful procession: the whole thing is called “moving of the cot”.
Moving the cot
But maybe the most important cultural characteristic of Daghestan is the living cultural practice of protecting one’s guests. Stemming from old times when travelling in the Caucasus mountains was not always safe, if one happens to come to a Daghestanian village one will be invited into a house, given food and shelter and will become kunaks with the master of the house. Kunak is not easy to translate. It means ‘guest’, but also ‘friend’. So I can say “I have a kunak in that village” meaning there is a person there who once was my guest (or vice versa) and now we are friends, so I can always count on having food and shelter in his house as much as he can in mine. In former times it was a duty for the master of the house to protect his kunak such that if anything were to happen to him, the perpetrator of the bad deed would answer to the house where the guest was staying. This system is still very much alive in Daghestan, and once I had eaten or slept in somebody’s house, I knew that I would be safe in that village and probably the neighbouring ones too.
When it comes to etymology, most words have a somewhat mundane route into a language: they either are retained from a direct ancestor or were borrowed at some point from another language. Within the latter category, these words tend to come in batches, often either through an intensive period of contact between peoples, as with the Old Norse loans into English, or through the importation of specific vocabulary which related to aspects of culture which were being borrowed from the group in question, such as e.g law terms deriving from the French used in English courts after the Norman Conquest.
However, every so often, there come along lexical items with a significantly more complex and idiosyncratic path into a language, and occasionally words may interplay with one another in interesting ways. We find such a complex interplay with galore and agogo.
Galore by itself is already an interesting form, as it is one of a small number of loanwords from Gaelic (likely specifically Scottish gu leòr) which does not have some kind of connection with Gaelic culture or geography. This expression can mean either ‘enough’ or ‘much, plenty’, and occurs in several constructions as a result. For instance, in Scottish Gaelic when asked ‘how are you?’, one might respond ceart gu leòr ‘all right, OK’, literally ‘right enough’.
This phrase, in a number of varying spellings such as gilore or gallore, appears to have begun to arrive in English in the mid 17th Century (or at least this is the date of the earliest citation in the Oxford English Dictionary). When this form was borrowed into English it underwent semantic shift and narrowing, coming to specifically mean ‘in abundance, plenty’, losing the sense of ‘enough’. It seems to have been somewhat colloquial in use, not being particularly frequent in writing, and is disproportionately concentrated in Scottish works, including an attestation in the journals of Walter Scott.
This form comes to its greatest in prominence in English through its use in a Compton Mackenzie novel and later Ealing comedy titled Whisky Galore! Both the novel and film centre on a remote Scottish island, and the novel in particular makes use of Gaelic throughout, so the use of ‘galore’ fits in well with the setting.
This work in particular, however, had a more interesting impact than simple popularity. As with many best-selling works, it received translations into other languages, and in this case the French translation was titled Whisky à-Gogo, deriving likely from the Old French gogue ‘fun’. This title then was itself used as the name of a nightclub in Paris, the world’s first discothèque. The concept rapidly grew in popularity, with Whisky à-Gogo venues spreading across the globe, as far as Papeete in Tahiti (and Cardiff!), the most famous probably being the the Whisky a Go Go on Sunset Strip in Hollywood. (In the English-speaking world gogo got split into two, possibly on false analogy with the verb ‘go’.)
But there’s only one Roadrunner…
From here on ‘a go go’ or just ‘go go’ became a by-word for everything hip and cool (or ‘groovy’) in the 1960s. Go-go dancers dance in go-go clubs, of course, but the meaning became more and more nebulous over time. In cinema, 1965 was a banner year, with Roadrunner a go-go up against Monster a go-go. This year also an unsuccessful attempt to extend this—word? phrase?—by analogy, with the notorious Batman parody Rat Pfink a Boo Boo. Nobody seems to have got this (not terribly good) joke, and on subsequent reissues the film was “corrected” to Rat Pfink and Boo Boo. (You’re reading this etymology here first. Even the director who came up with the title didn’t realize it, but we’re linguists, we know better.) But the shelf life of terms denoting popular trends is short, and anyone using it now probably means for it to lend antiquated flavour of the swinging 60s. Contrast with galore, which retains its more generic use and seems unlikely to drop out of common usage in the near future.
You may be familiar with the fact that the Germans refer to themselves as Deutsch and their country as Deutschland, and we find this term also in most other Germanic languages, such as Dutch Duits or Swedish Tysk, as well as Italian Tedesco. However, there are many other names in other parts of Europe. The French and Spaniards call them Allemand/Alemán, as do the Welsh with Almaenaidd; the various Slavic languages share a different term again, seen in e.g. Polish Niemiec or Russian Nemets. In the Baltic the Lithuanians and Latvians have their own terms not seen anywhere else (Vokietis and Vācijis respectively), while in Finland and Estonia they call them Saksi. We could also add some assorted forms from smaller languages, such as Miksas from Old Prussian, an extinct sister language to Lithuanian and Latvian.
The Deutsches Eck, or ‘German corner’, in Koblenz
Now, it is not unusual for inhabitants of a country to refer to themselves and their country with a different form from that used by outsiders (when was the last time you called China Zhongguo or India Bharat?). What is particularly notable about the German case, however, is the diversity even among its immediate neighbours. Contrast e.g. France, where everyone uses some form of derivative of Latin Francia (after the Germanic tribe the Franks), though the Greeks still call it Gallia after the Roman province of Gaul. Similarly, most call Spain some form derived from Hispania and Italy one from Italia. So, this diversity in names for the Germans requires some explanation.
Whence this plethora of terms? A consideration of history leads us to our answer. Recall that the modern country of Germany is a relatively recent creation, only being officially united in the mid 19th century by Otto von Bismarck. While there was a political entity that occupied the area in the form of the Holy Roman Empire it was only a relatively loose collection of small states, and prior to that the area was inhabited by a number of distinct Germanic-speaking peoples.
As a result, some of these names derive from the individual groups or tribes which lived in part of the area: so in the Western Romance and Brittonic Celtic languages the name of the Alemanni tribe was applied to the Germans as a whole. The same process occurred in the northeast with the Baltic Finns and the Saxons: not only were the Saxons the nearest group, but also, due to a combination of the Hanseatic League controlling trade through the Baltic and the anti-pagan crusading of the Teutonic Knights (another Deutsch-relative, see below), many Saxons came to settle in the Eastern Baltic, with some of their descendants still living in Estonia and Latvia today. Some small varieties show different groups again: some of the smaller Germanic varieties use a form derived from Prussian, after the state which ended up uniting the German peoples.
English takes a slightly different approach, deriving the term Germans from the Latin name of the region; Germania. This term included two Roman provinces covering much of modern-day Belgium, Switzerland, parts of eastern France and the Rhineland in modern Germany, as well as applying to the larger swathe of barbarian territories further east. Interestingly, several languages use this term to refer to Germany the country despite using a different term to refer to the Germans: Italian and Russian are the most notable examples.
We find a different source again with the Slavic Nemets terms. There is again some dispute in origin, but the general consensus is that it derives from a Slavic root *němъ meaning ‘mute’, itself of contested origin. The meaning likely was not ‘mute’ necessarily, but rather simply denoted that these groups were not Slavic-speaking. This puts in a similar group to the word ‘barbarian’ in fact, which derives from a Greek word meaning ‘those who go bar-bar/talk incomprehensibly’. Similar origins to do with ‘talking’ are likely behind the Baltic Vok-/Vāc-/Miks- forms as well.
Finally, what of German ‘Deutsch’? Well, as is the case with many endonyms it is a relatively simple and self-referential etymology. It ultimately derives from an Indo-European root *tewteh2 meaning simply ‘people’, which shows up also in e.g. Irish túath with the same meaning. This form may also be the source of Romance forms such as Spanish todo or French tout meaning ‘everyone/everything’. This root even survives in Slavic, in Russian giving the form čužoj, meaning ‘foreign, alien’. This ended up as Germanic *þeudō, which through an adjective formation *þiudiskaz meaning something like ‘of the people’ ultimately leads to the modern German form. This form also gives Latin Teutones, a likely Celtic or Germanic tribe which lived in the North German region and was encountered by the Romans early in their expansion northwards.
So, as with many other terms, such as the aubergine words which have been discussed here before, the differences between languages are reflective of a complex history. In this case the wide array of disparate terms of different etymologies reflects the complex history of the entity involved, specifically the absence of a country that even called itself ‘Germany’ until the modern era, as well as the extent to which different groups of ethnic Germans have moved about in Europe.
Have you ever encountered the form twote as a past tense of the verb to tweet? It is something of a meme on Twitter, and a live example of analogy (and its mysteries). However surprising the form may sound if you have never encountered it, it has been the prescribed one for a long time:
It is clear that this unusual form replacing tweeted is some sort of form, but why specifically twote? I saw here and there a reference to the verb to yeet, a slang verb very popular on the internet and meaning more or less “to throw”. Rather than a regular form yeeted, the past for to yeet is often taken to be yote. The choice of an irregular form is probably meant to produce a comedic effect.
This, precisely, is analogical production: creating a new form (twote) by extending a contrast seen in other words (yeet/yote). Analogy is a central topic in my research. I have been trying to answer questions such as: How do we decide what form to use ? How difficult is it to guess? How does this contribute to language change?
But first, have you answered the poll?
Here at the SMG we need to know: What do you think the past tense of 'I tweet' is?
To investigate further why we would say twote rather than tweeted, I took out my PhD software (Qumin). Based on 6064 examples of English verbs1, I asked Qumin to produce and rank possible past forms of tweet2. To do so, it read through examples to construct analogical rules (I call them patterns), then evaluated the probability of each rule among the words which sound like tweet.
Qumin found four options3: tweeted (/twiːtɪd/), by analogy with 32 similar words, such as greet/greeted; twet (/twɛt/), by analogy with words like meet/met; tweet (/twiːt/) by analogy with words like beat/beat, finally twote (/twəˑʊt/), by analogy with yeet. Figure 1 provides their ranking (in ascending order) according to Qumin, with the associated probabilities.
Figure 1. Qumin’s ranking of the probability for potential past forms of to tweet
As we can see, Qumin finds twote to be the least likely solution. This is a reasonable position overall (indeed, tweeted is the regular form), so why would both the official Twitter account and many Twitter users (including several linguists) prefer twote to tweeted?
But Qumin has no idea what is cool, a factor which makes yeet/yote (already a slang word, used on the internet) a particularly appealing choice. Moreover, Qumin has no access to semantic similarity, which could also play a role. Verbs that have similar meanings can be preferred as support for the analogy. In the current case, both speak/spoke and write/wrote have similar pasts to twote, which might help make it sound acceptable. Some speakers seem to be aware of these factors, as seen in the tweet above.
Is it twankt or twunkt? I'm thinking about the past-tense of tweet.
Are most speakers aware of the variant twote and using it? Before concluding that the model is mistaken, we need to observe what speakers actually use. Indeed, only usage truly determines “what is the past of tweet”. For this, I turn to (automatically) sifting through Twitter data.
A few problems: first, the form “tweet” is also a noun, and identical to the present tense of the verb. Second, “twet” is attested (sometimes as “twett”), but mostly as a synonym for the noun “tweet” (often in a playful “lolcat” style), or as a present verbal form, with a few exceptions, usually of a meta nature (see tweets below). I couldn’t find a way to automatically distinguish these from past forms while also managing within the Twitter API limits. Thus, I left out both from the search entirely. This leaves only our two main contestants.
If it's not already been formally done, I should now like to declare the past tense of "tweet" to be "twet"
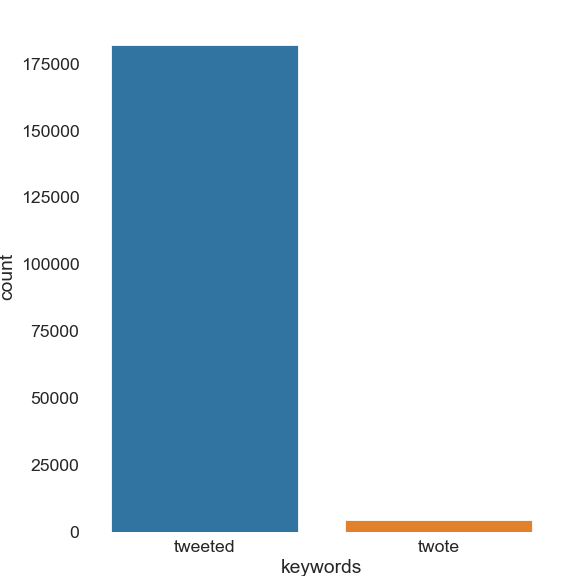
I extracted as many recent tweets containing tweeted or twote as Twitter would let me — around 300 000 tweets twotten between the 26th of August and the 3rd of September. 186777 tweets remained after refining the search4. Of these, less than 5000 contain twote:
Counts of tweets containing either of two possible pasts for the verb “to tweet” in the past few days on twitter (mentions excluded).
As you can see, the tweeted bar completely dwarfs the other one. However amusing and fitting twote may be, and despite @Twitter’s prescription (but conforming with Qumin’s prediction), the regular past form is by far the most used, even on the platform itself, which lends itself to playful and impactful statements. This easily closes this particular English Past Tense Debate. If only it were always this simple!
The English verb data I used includes only the present and past tenses, and is derived from the CELEX 2 dataset, as used in my PhD dissertation and manually supplemented by the forms for “yeet”. The CELEX2 dataset is commercial, and I can not distribute it. [↩]
The code I used for this blog post is available here, but not the dataset itself. Note that for scientific reasons I won’t discuss here, this software works on sounds, not orthography. [↩]
One last possibility has been ignored by this polite software, a form which follows the pattern of sit/sat. I see it used from time to time for its comic effect, but it does not seem at all frequent enough to be a real contestant (and I do not recommend searching this keyword on Twitter). [↩]
Since there has been a lot of discussion on the correct form, I exclude all clear cases of mentions. I count as mentions any occurrences wrapped in quotations, co-occurring with alternate forms, mentioning past tense, or with a hashtag. Moreover, with the forms in –ed, it is likely that the past participle would be identical, but for twote, the past participle could well be twotten. To reduce the bias due to the presence of more past participles in the usage of tweeted, I also exclude all contexts where the word is preceded by the auxiliary forms has, have, had, is, are, was, were, possibly separated by an adverb. [↩]
Linguists spend most of the year stuck to the computer monitor: analyzing data, reading, or writing papers. But the time comes when we have to roll up our sleeves and find our sense of adventure. Personally, this is my favorite time of the year! Going on a linguistic field trip often involves living in a local community and immersing yourself in a completely different culture. You learn so much about the customs, traditions, beliefs… And, of course, you learn a lot about the language.
South-Eastern Serbia, one of our fieldwork destinations
However, there seems to be a limitation. What should you do if you study the history of some phenomenon? If you are not only interested in how the system is now, but also in how it was before? We cannot jump into a time machine and reemerge in the 15th-century world to run our questionnaires there. So surely historical texts and comparative grammars are the only way to go, and fieldwork is not useful here… Or is it? Well, it turns out that a field trip can be very helpful for extrapolating historical data, but only if you are lucky with the location. Fortunately, I am!
My lucky place
In the project “Declining case: Inflectional loss in progress”, my colleagues and I study dialects of Serbian and Bulgarian. These two languages have been posing linguists a headache for more than a century already. Although they are quite closely related and are spoken side by side, they have a lot of significant differences in the grammatical structure. To name some, (1) Bulgarian has articles (like English a and the), while Serbian does not, (2) Serbian uses infinitives, while Bulgarian does not, and (3) Serbian nouns have a fully-fledged morphological case system, while Bulgarian nouns do not inflect for case at all. People still argue about the exact reasons for this, but there is a general consensus that Bulgarian has undergone certain changes because it is located in the so-called Balkan linguistic area. A cool thing is that there is no sharp border between the innovative grammatical system of Bulgarian and the conservative system of Serbian. Rather, in the geographical zone on both sides of the Serbian-Bulgarian border, we see a variety of intermediate systems.
Let us see how it works on the example of the case inflection, which we study in our project. Cases are used in some languages to mark grammatical relations, such as subject or object. Serbian does it in this way, while Bulgarian uses prepositions instead. Take a look at this table, where the word ‘Cyprus’ appears in different contexts. See how in Serbian this word changes the ending depending on the context and in Bulgarian it keeps the same form? Just like in English!
Serbian
Bulgarian
Translation
vole Kipar
xaresvat Kipâr
‘They like Cyprus’
stanovništvo Kipra
naselenieto na Kipâr
‘The population of Cyprus’
pomažu Kipru
pomagat na Kipâr
‘They help Cyprus’
upravljaju Kiprom
upravljat Kipâr
‘They govern in Cyprus’
Overall, Serbian has six cases, while Bulgarian uses one general case form. So, what do we see in the transitional zone? Well, depending on where exactly we look, we find different systems. For example, in a more western part of the transitional area, we can meet a system where they use three cases, while in a more eastern part we can find a two-case system.
Serbian
Transitional system 1
Transitional system 2
Bulgarian
Case 1
Case 1
Case 1
No case
Case 2
Case 2
Case 2
Case 3
Case 3
Case 4
Case 5
Case 6
What does it mean? It looks like standard Bulgarian at some point in its development lost its case marking on nouns completely, while the dialects in the transitional zone underwent this change to a smaller degree. The further west we move, the less this change affected the dialect. This situation created an unprecedented opportunity for us. We can go to different places in the transitional zone, compare their systems to each other, and use this comparison to create a historical model of the loss of case. We do not need a time machine, we have the different stages of this process living side by side today!
This summer, for example, I went to the municipality of Brus, which is located in Southern Serbia. There I witnessed the initial stages of case decline. People in Brus still use all six cases, but sometimes replace one with another, or insert a preposition in phrases where standard Serbian would not have it. While interviewing people, I learned about some fascinating traditions in this area. For example, one of the oldest customs at the wedding is to put an apple at the highest point in the backyard, and the groom has to hit the apple with a gun. If he fails to do so, he is not going to get his bride!
Apparently, in earlier times, a wedding would last for several days and involve all sorts of rituals. Unfortunately, most of them are lost now. It would be so nice to see how a wedding was celebrated then! But for this, I am afraid, we do need a time machine.
Careful who you climb a tree near: Respect and taboo in Vanuatu
One humid afternoon, during breadfruit season in North Ambrym, my language teacher, Isaiah, and I were on the lookout for some ripe breadfruit to roast for lunch. Our path led past his nephew, George’s, house. Isaiah saw some ripe breadfruit in the tree next to where George was sitting on his veranda. Isaiah wanted to get the breadfruit, but said that because George was there, he couldn’t, and we would have to find some others instead. I asked if it was George’s breadfruit tree, and that’s why he didn’t want to take it when George was around. Isaiah said no; rather, the problem was if we went up the tree when George was underneath, then he would have to pay a small fine to George. Over a lunch of roasted and pounded breadfruit called wuwu, Isaiah explained further. It was to do with respect and taboo.
Respect in language takes many forms. There is the tu/vous distinction in French, where tu is the informal form of ‘you (singular)’ and is used with friends and those younger than you, whereas vous ‘you (plural)’ is formal and is used with those elder or senior than you and for people you don’t know. Similar distinctions are found with the German du/Sie. English doesn’t have a grammatical distinction in politeness like this, but uses different sentence structures to express politeness: compare pass me the salt please with could you please pass me the salt, or the even more polite would you be so kind as to pass me the salt please.
Now let’s get back to eating that heavy sticky coconut-cream-slathered wuwu with Isaiah. He told me that you must respect certain members of your extended family by showing physical politeness. Respect is translated as tengnean in the language of North Ambrym. The people who you must respect are your taboo family, described by the verb gorrne. Respect for your taboo family on Ambrym is realised in different ways – through physical restrictions and through language. The family members who command the most respect are your sister’s son or your husband’s brother.
The physical restrictions with a taboo relative include:
You can’t eat in front of them
You can’t joke with them
You can’t climb over them, or be physically higher than them
You can’t sleep in front of them
You can’t enter their house
But what about restrictions on language? The normal translation of ‘hello’ in North Ambrym would be neng le, which literally means ‘you there’, using neng, the singular form of ‘you’. But you are not allowed to say this to your taboo relatives. Instead, you must say gōmōro le using the dual form of ‘you’, meaning ‘you two there’, even though you are addressing one person. This is similar to French or German mentioned earlier. However, North Ambrym, like many Oceanic languages, not only has singular and dual, but also paucal, meaning ‘a few’, and plural pronouns. Of these possibilities, the dual is used for respect, not the plural as in French or German.
Respect is not confined to pronouns such as ‘you’; people also have to avoid using certain words in front of their taboo relatives. For example, if your sister’s son came, and you invited him to sit down and have some food, you would have to avoid certain verbs, such as taa ‘sit’ or ngene ‘eat’. You would use lingi ‘put’ instead of ‘sit’ and tewene ‘make’ instead of ‘eat’ so the whole sentence would be rephrased as ‘you-two come and put your-dual-self here and make the food’.
You must also avoid certain words concerning body parts, specifically words relating to parts of the head. Normally when talking about body parts in North Ambrym you would use a bound noun – a type of noun which specifies who owns the body part – so the word for ‘tooth’ would be lowo-n ‘his/her tooth’, lowo-m ‘your tooth’, or lowo-ng ‘my tooth’. The end of the noun (-n/-m/-ng in this example) indicates whose tooth it is. But these words are not allowed when talking in front of your taboo relatives. Instead, you could use a free form of the noun, such as leo ‘tooth’.
Another avoidance strategy is to change a verb to a noun using a special nominalising prefix a- that appears on the beginning of the word and turns it into a noun. The verb itself is also reduplicated. For example, the verb ta ‘cut’ can be turned into a noun atata ‘tooth’ (literally ‘thing for cutting’).
Finally, a more idiomatic expression could be used; in this case, tooth is replaced by tō which literally translates as ‘limpet shell (traditionally used as a vegetable grater)’ or teye ‘clam shell/axe’ as a way of avoiding the bound form for ‘tooth’.
Here’s a handy table to help you get your head (or just head!) around avoiding the bound forms.
Bound
Free
Nominalisation
Idiomatic
rralnye-n ‘his, her ear’
teleng ‘ear’
arorongta ‘thing for listening, headphones’
harrlengleng ‘listening’
lowon ‘his, her tooth’
leo ‘tooth’
atata ‘thing for cutting’
tō ‘limpet shell (used as a grater)’
teye ‘clam shell, axe’
metan ‘his, her eye’
marr ‘eye’
ateter ‘thing for seeing, glasses’
hal ‘road, path’
glas ‘glasses’
guhun ‘his, her nose’
kuu ‘nose’
akunuknuu ‘thing for smelling’
woulun ‘his, her hair’
wovyul ‘hair’
ōrr ge mre ‘place which is above’
As time passes, so do traditions, and the older generations mourn the loss of respecting their taboo relatives. They complain that younger generations now joke with their taboo relatives or put their arms around them. This art of speaking is being lost and the physical taboos are being eroded. However, this change is not new and has been going on for several generations. Some of the more extreme forms of respect are almost out of living memory. One of the village elders, Ephraim, recounted a memory of seeing how his grandmother, Mataran, displayed respect when returning from the garden, with her vegetables one day. When she approached her home, she saw that one of her husband’s brothers was there. She came close, then crawled the rest of the way past her husband’s brother with her basket of vegetables over her shoulder, until she was in her doorway before standing up again.
So the next time you are in Vanuatu, take care when climbing trees and make sure you know which of your relatives are nearby!