“Are potatoes ‘badder’ than usual in the UK atm?” This was the question posed by a reddit user last week. Despite the scare quotes, this use of the word ‘badder’ was met with general mockery (as well as some genuine attempts to answer the question: the wet weather has caused poor growing conditions for root veg this year, if you were wondering). Yet the intended meaning is completely clear to English speakers; more so than if it had been phrased ‘are potatoes worse than usual?’.
In fact, ‘badder’ has seen a big increase in use since the mid 20th century (although it’s been around for a long time, and was even used by Chaucer). Google books offers numerous titles from recent years such as Bigger and badder: a billionaire romance (2016), How to be a badder bitch (2018) and the Bad guys even badder box (2019). What these titles have in common is that ‘bad’ is used with a special meaning as part of a set phrase. ‘Bad guy’ evokes a stock villain from a story, not just any old guy who happens to be bad. A ‘bad bitch’ is a tough, empowered woman. Thus a ‘badder guy’ is even more villainous, and a ‘badder bitch’ is even cooler and tougher. ‘Can you imagine a worse bitch than Helen?’ makes it crystal clear that the speaker doesn’t like Helen, but ‘can you imagine a badder bitch than Helen?’ implies admiration instead.
These are examples of what linguists call lexicalisation. ‘Bad guy’ and ‘bad bitch’ have become set phrases whose meaning is more than just the sum of their individual parts. In other words, the meaning of ‘bad guy’ is not just the meaning of ‘bad’ + ‘guy’, and would have to be listed as a separate entry in a dictionary. In a sense, it behaves as a single word (which is also betrayed by its special stress pattern: a bad guy is a guy who is bad, while a bad guy is a villain). This is even clearer for ‘bad bitch’: both bitch and bad have strongly negative connotations, but bad bitch is positive.
The coinage of ‘badder bitch’ reveals a change that has already happened under the surface. Two words have become one phrase, with its own unpredictable meaning. Bad and worse are forms of the same lexeme, in the sense that they’d be listed under the same dictionary entry: they are members of the same paradigm. ‘Badder bitch’ shows that changes in meaning can happen to individual forms in the paradigm, rather than lexemes, otherwise ‘worse bitch’ would automatically take on the meaning of ‘bad bitch’. Bad in the newly lexicalised bad bitch starts off its life without any comparative form, so you’ve got to make up something new if you want to use one.
Something similar can be seen in examples like straight or wrought, which started off life as past participles of the verbs stretch and work. Straight in a sentence like ‘I have straight the string’ was regularised to stretched, and wrought to worked. But the forms straight and wrought were left behind in usages like ‘the straight string’ or ‘the wrought iron’, revealing that they had become lexicalised as adjectives in their own right.
Back to badder potatoes. Bad in the context ‘a bad potato/apple/egg (etc.)’ has a special sense of ‘rotten’ that is somewhat lexicalised, hence ‘badder potatoes’ are more rotten, while ‘worse potatoes’ could be worse in any number of ways. Either that, or potatoes are becoming meaner and more villainous as a result of the miserable weather, which frankly I can relate to. Let’s remain vigilant, just in case.
A villainous potato coming to get you, courtesy of https://hotpot.ai/art-generator
When you want to look up a word, how do you go about it? The dictionary is organised by the first letter of the word, so that is what you consider first. And when you want to compare languages, what is the first thing to catch your eye? Again, the first sound. Thus, when looking at a set of words like English fish, father, full, Latin piscis, pater, plenus and Scottish Gaelic iasg, athair, làn, the fact that f- in English corresponds to p- in Latin and zero in Scottish Gaelic spring immediately to our attention, reading as we do from left to right.
Thus, we might presume that the beginning of a word is somehow especially stable, and that sounds which appear at the beginning of a word are a good first indicator of etymology. However, in fact the beginning of a word is not so immutable as you might suppose. Famously, Celtic languages have initial consonant mutations, which alters the initial consonant of a word in regular ways depending on grammatical context. So in Welsh, while ‘Wales’ is Cymru, ‘Welcome to Wales’ is Croeso i Gymru, ‘in Wales’ is yng Nghymru and ‘England and Wales’ is Lloegr a Chymru. This is interesting enough, but not the only way that the start of a word may be altered in languages. Indeed, we don’t even have to leave English to find examples of a different phenomenon that can take place in the history of an individual word.
Let us take a word like adder (the snake specifically, not someone that does addition!). We can look for cognates in closely-related languages, but we are immediately presented with a problem: German Natter, Frisian njirre and Icelandic naðra all seem like they should be related (all being words for ‘snake’), but what’s with this n- at the beginning of the word? Things only get more confusing when we notice words like Latin natrix ‘watersnake’, Welsh neidr or Scottish Gaelic nathair, all again showing an n-. Finally, when we look at Old English we find that the word there is næddre! What’s going on? We know that in general English n- doesn’t do anything particularly strange and it certainly doesn’t just disappear from the beginnings of words, as evidenced by numerous forms like name, night, nest, new, and nine which have had an n- since Proto-Indo-European!
The answer lies in a phenomenon that linguists call ‘rebracketing’. This is a fairly straightforward notion; linguists already make use of brackets to show the internal structure of phrases, thus any change in the structure of the phrase is notated by a change in the arrangement of the brackets. (It will be noted that some authors, including the Oxford English Dictionary, use the term metanalysis instead, but the meaning is the same.)
In the case of adder, the confusion comes from the indefinite article, which in English is a before words beginning with a consonant and an before words beginning with a vowel. Thus, if a word begins with an n-, this can find itself being rebracketed onto the indefinite article: thus [a [nadder]] becomes [a-n [adder]]. And this isn’t the only word where this has happened in English either: thus [a [napron]] (from French napperon) became [a-n [apron]]. On the flipside, the opposite is also found, where the -n from the indefinite article finds itself attached to the front of a word that originally began with a vowel, e.g. [an [ewt]] → [a [n-ewt]] or [an [ekename]] → [a [n-ickname]].
An ewt!
Some of these forms have since become the predominant forms of their respective words, but such is not always the case. For example, uncle derives from a French word oncle, ultimately from Latin avunculus. However, those who are familiar with their Shakespeare will remember the Fool in King Lear, who refers to the title character as ‘nuncle’. Here the reanalysis, rather than from the indefinite article, seems to have been on the basis of possessive pronouns mine and thine, which are particularly frequently used with kind terms: thus [mine [uncle]] becomes [my [nuncle]]. Yet, unlike with the other examples, this has not stuck around, perhaps because the other possessive pronouns (his, her, our, your, their) which would not have motivated this reanalysis; thus the original uncle stuck around and was able to reassert itself.
Nor is English alone in exhibiting these kinds of change. In the adder~nadder case, the same reanalysis has also taken place in Dutch and Low German, also spelt adder in both cases. Similarly, Arabic nāranj was borrowed into Spanish as Naranja, but this underwent rebracketing when it was borrowed into Italian as arancia, and it was from there that the word spread to the rest of Europe, including English orange.
French provides us with an especially interesting example of layered reanalyses in a single word. In Old French, unicorne was reanalysed as beginning with the indefinite article (which is in a sense not incorrect: the literal meaning of the word is ‘one-horn’ and ‘one’ is the source of the French indefinite article, as well as indefinite articles in general cross-linguistically). This left a form icorne, which would contract with the definite article, giving l’icorne ‘the unicorn’. However, at some point, this contracted form with the article came to be reanalysed as the base of the noun itself, with the result that licorne is now simply the French for ‘unicorn’, leading to constructions such as la licorne ‘the unicorn’ where a historical definite article appears ‘doubled up’!
Some of the most complex cases of rebracketing can be found in Scottish Gaelic. Here we have a number of potential sources of rebracketing, both because the definite article changes depending on the following noun and because of the interaction of the definite article and the mutation system.
Firstly, with vowel-initial masculine noun the definite article prefixes a t- e.g. eun ‘bird’ but an t-eun ‘the bird’. Unsurprisingly, based on the examples we have seen above, this prefixed t- has in many cases become attached to the noun. Interestingly this is particularly common in loanwords from Old Norse, such as talla ‘hall’ from hǫll, tòb ‘small bay’ from hóp (òb is also common) and tolm ‘small islet’ from holmr, as well as other loans such as taigeis ‘haggis’ and tobha ‘hoe’ from English.
In a similar vein, one of the components of consonant mutation is Scottish Gaelic is that an f sound disappears (though is still written as fh). As a result, a larger number of words that began with vowels in Old Irish have acquired an f- in Scottish Gaelic, e.g. áinne ‘ring’, uar ‘cold’ and íaru ‘squirrel’ have become fáinne, fuar and feòrag respectively, as if an áinne uar ‘the cold ring’ was really an fháinne fhuar. Many of the words have undergone the same kinds of changes in Irish and Manx, though not all languages agree on which (e.g. Irish also has fáinne and fuar but iora respectively).
And, as in English, words that begin with n- can find this consonant being rebracketed as part of the article an. However, once this n- has been rebracketed, this now vowel-initial word can undergo the same kinds of mutation-based reshaping as an originally vowel initial word. Perhaps the most extreme example of this is ‘nettle’, which was nenaid in Old Irish, but in Scottish Gaelic can be (depending on who you ask) any of neanntag, eanntag (with the n- rebracketed away), feanntag (with the f- appended by lenition reversal) and deanntag (where the d- is apparently a hypercorrective reversal of a process of nasalisation in the Northwestern dialects)!
neanntag, eanntag, feanntag or deanntag?
So, when searching around for a word in a dictionary or an old text, be cautious; simply looking for the first consonant to give you a clue might be misleading when taken out of context. Furthermore, instances like these make clear that language is primarily a spoken phenomenon and the kinds of changes that we see reflect that: while in a written text the different between a newt and an ewt is obvious, in spoken language the question of where one word ends and the nexts begins is not so straightforward as a casual glance at a dictionary might suggest. Perhaps this should then make us ponder further how much written language is a direct reflection of spoken language versus being at least partially arbitrary choices made by the writers.
Last month, the Guildford Shakespeare Company put on a production of Richard II, a fascinating tale of political strife and the perils of having a leader lacking in competence when the country is in crisis. Sound familiar? In any case, this got me thinking about the name Richard and its many etymological links.
First with the name Richard. It’s borrowed from French, but it didn’t start there. In fact it is one of a number of French words that was borrowed from Germanic, deriving from Frankish *Rīkahard, meaning ‘hard/brave king’. This also gives modern German Richard and through the travels of the Goths and Vandals also made its way into Spanish as Ricardo and Italian as Riccardo. The first part of this name, the *rīk- ‘ruler’ part, in other derivations also gives words like German Reich and Dutch rijk, both meaning ‘empire’ or ‘kingdom’, which in English is also found as the ‘domain, kingdom’ suffix -ry, as in Jewry ‘the Kingdom of the Jews’. As different derivation again gives us English rich, something you’d rather expect a king to be. As a component of names it is ubiquitous in Germanic, such as in Old English Godric ‘God(ly) king’, Wulfric ‘Wolf-king’ and Theodric ‘King of the people’. This last one turns up in German as Dietrich and, again courtesy of the Franks, through French Thierry comes into English as Terry (see also my previous post on the Germans for more on this Theod-).
But it is not only Germanic languages that have this root. Indeed, some form of it crops up across the Indo-European language family, usually meaning something like ‘king’ or ‘ruler’. In Celtic (from which Germanic likely borrowed the rīk- words) we find e.g. rí in Irish and rhi in Welsh, both meaning king. In Gaulish, rulers such as Vercingetorix and Ambiorix had an earlier form –rix it as part of their name, and in a reduced form we find the same in the Welsh surname Tudor, originally meaning ‘ruler of the people’ and thus cognate with Theodric/Dietrich/Terry.
In Latin too we find rēx, again meaning ‘king’ or ‘ruler’. This form survives as such in many modern Romance languages, for example Spanish rey and French roi. We also get two separate adjectives in English: regal from Latin and royal from French. Further afield, we find this word cropping up as far away as India, in the form of Sanskrit rāja, once again a ‘king’ word, as well as rāṣṭrá, a ‘kingdom’.
All of these forms can be traced back to a form in Proto-Indo-European (the reconstructed ancestor of all of these languages), which we represent as *h3rḗǵs. In the terminology of Indo-European studies this is an ‘athematic root noun’, meaning a short root without additional derivational suffixes onto which inflectional endings such as the nominative singular *-s are suffixed directly, rather than having an additional ‘theme vowel’ *-o inbetween. As with many such forms in Proto-Indo-European, when we isolate the root itself, *h3reg-, which probably meant something like ‘stretch out the arm, direct’, we can find even more related derivations.
Adding a thematic vowel *-e/o- we get a verb which shows up in Latin as regō ‘rule, govern, direct’, along with an array of derived nouns which we have inn English. We have the agent noun rector, the instrument noun rule (from a French reflex of Latin rēgula) and the abstract noun regimen. Additionally, we have prefixed verbs such as dīrigō,ērigō and corrigō, which through their respective supine forms dīrēctum, ērēctum and corrēctum give us English ‘direct’, ‘erect’ and ‘correct’ respectively.
Germanic, meanwhile, provides us with a different set of reflexes of this verb. While we have already seen the rich set relating to wealth and kingship, the ‘straighten’ meaning of *h3reg- results in other interesting links. We have the (originally separate) verb and noun rake, a device for making straight lines, and the former participle right, originally meaning ‘straightened, directed’. Then we have reckon, perhaps a natural extension of the metaphor of lining things up in order to count them. Finally, from a causative ‘make straighten up’ we have reach (as if ‘straightening out one’s arm’).
This here is the greatest joy of etymology for me; by untangling these webs of relationships, we can show how so much of our vocabulary results from variations upon a common root. It reminds us of the continual creativity involved in using language and, by extension, the creativity of language users, i.e., humans.
A lot of the work that linguists do involves taking a language as it is spoken at a particular time, finding generalizations about how it operates, and coming up with abstractions to make sense of them. In English, for example, we identify a category of ‘number’ (with possible values ‘singular’ and ‘plural’); and we do that because in many ways the relationship between cat and cats is the same as that between mouse and mice, man and men, and so on, meaning that it would be useful to treat all of these pairings as specific examples of a more general phenomenon. We can then make the further generalization that whatever this linguistic concept of ‘number’ really is, it is not only relevant to nouns but also to verbs, and to some other items too – because English speakers all know that this cat scratches whereas these cats scratch, and you can’t have any other combination like *these cat scratch.
This bat scratches
Once you start looking, you discover layer upon layer of generalizations like these, and you need more and more abstractions in order to take care of them all. This all gives rise to a view of language as a kind of machine built out of abstract principles, all coexisting at the same time inside a speaker’s head. On that basis, we can ask questions like: are there any principles that all languages use? Does having pattern X always go along with having pattern Y? Are there any generalizations that you can easily come up with, but that turn out not to be found anywhere? What does all this tell us about human psychology?
But that is not the only approach to language we could take. While we can point to a general principle of English to explain what is wrong with these cat, there is no similar principle explaining why we refer to the meowing, purring, scratching creature as a cat in the first place. The word cat has nothing feline about it, and the fact that we use that sequence of sounds – rather than e.g. tac – is not based on some higher-level truth that applies for all English speakers right now: instead, the ‘explanation’ is rooted in the fact that this is the word we happened to inherit from earlier generations of speakers.
General Ambrose Burnside (1824-1881)
So studying the etymology of individual words serves as a good reminder that as well as an abstract, principled system residing in human minds, every language is also a contingent historical artefact, shaped by the peoples and cultures of the past.1 Nothing makes this more obvious than the continued existence of ordinary vocabulary items that commemorate individuals from centuries gone by – often without modern-day speakers even knowing it. In English, sandwiches are named after the Earl of Sandwich, wellingtons are named after the Duke of Wellington, and cardigans are named after the Earl of Cardigan; and the parallelism here says something about the locus of cultural influence in Georgian and Victorian Britain. More cryptically, sideburns owe their name to a General Burnside of the US Army, justly famed for his facial hair; algorithms celebrate the Persian mathematician al-Khwarizmi; and Duns Scotus, although a towering figure of medieval philosophy, now lives on in the word dunce popularized by his academic opponents.2
But which historical figure has had the greatest success of all in getting his name woven into the fabric of modern English? I reckon that, against all the odds, it could well be this Guy.
While all English speakers are familiar with the word guy as an informal word corresponding to man, probably not that many know that it can be traced back to a historical figure from 400 years ago who, in a modern context, would be called a religious terrorist. Guy Fawkes was one of the conspirators in the ‘Gunpowder Plot’ of November 1605: with the aim of installing a Catholic monarchy, they planned to assassinate England’s Protestant king, James I, by blowing up Parliament with him inside. Fawkes was not one of the leaders of the conspiracy, but he was the one caught red-handed with the gunpowder; as a result, one cultural legacy of the plot’s failure is the celebration every 5th November (principally in the UK) of Guy Fawkes Night, which commonly involves letting off fireworks and setting a bonfire on which a crude effigy of Fawkes was traditionally burnt.
But how did the name of one specific Guy, for a while the most detested man in the English-speaking world, end up becoming a ubiquitous informal term applying to any man? The crucial factor is the effigy. It is unsurprising that this came to be called a Guy, ‘in honour’ of the man himself; but by the 19th century, the word was also being used to refer to actual men who dressed badly enough to earn the same label, in the way one might jokingly liken someone to a scarecrow (one British woman writing home from Madras in 1836 commented: ‘The gentlemen are all ‘rigged Tropical’,… grisly Guys some of them turn out!’). It is not a big step from there to using guy as a humorous and, eventually, just a colloquial word for men in general.3
Procession of a Guy (1864)
And of course the story does not stop there. While aguy is still almost always a man, for many speakers the plural guys can now refer to people in general, especially as a term of address. The idea that a word with such unambiguously masculine origins could ever be treated as gender-neutral has been something of a talking point in recent years, as in this article from The Atlantic about the rights and wrongs of greeting women with a friendly ‘hey guys’; but the fact that it is debated at all shows that it is happening. In fact, there is good reason to think that in some varieties of English, you-guys is being adopted as a plural form of the personal pronoun you: one piece of evidence is the existence of special possessive forms like your-guys’s, a distinctively plural version of your.
It is interesting to notice that the rise of non-standard you-guys, not unlike y’all and youse, goes some way towards ‘fixing’ an anomaly within modern English as a system: almost all nouns, and all other personal pronouns, have distinct singular and plural forms, whereas the standard language currently has the same form you doing double duty as both singular and plural. Any one of these plural versions of you might eventually win out, further strengthening the (already pretty reliable) generalization that English singulars and plurals are formally distinct. This just goes to show that the two ways of looking at language – as a synchronic system, and as a historical object – need to complement each other if we really want to understand what is going on. At the same time, it is fun to think of linguists of the distant future researching the poorly attested Ancient English language of the twenty-second century, and wondering where the mysterious personal pronoun yugaiz came from. Would anyone who didn’t know the facts dare to suggest that the second syllable of this gender-neutral plural pronoun came from the given name of a singular male criminal, executed many centuries before?
For example, cat itself seems to be traceable back to an ancient language of North Africa, reflecting the fact that cats were household animals among the Egyptians for millennia before they became popular mousers in Europe. [↩]
Of course, it is no accident that all of these examples feature men. Relatively few women in history have had the opportunity to turn into items of English vocabulary; in fact, fictional female characters – largely from classical mythology – have had much greater success, giving us e.g. calypso, rhea and Europe. [↩]
A similar thing also happened to the word joker in the 19th century, though it didn’t get as far as guy: that suggests that sentences containing guy would once have had the same ring to them as Who’s this joker?; and then some joker turns upand says… [↩]
Have you ever encountered the form twote as a past tense of the verb to tweet? It is something of a meme on Twitter, and a live example of analogy (and its mysteries). However surprising the form may sound if you have never encountered it, it has been the prescribed one for a long time:
It is clear that this unusual form replacing tweeted is some sort of form, but why specifically twote? I saw here and there a reference to the verb to yeet, a slang verb very popular on the internet and meaning more or less “to throw”. Rather than a regular form yeeted, the past for to yeet is often taken to be yote. The choice of an irregular form is probably meant to produce a comedic effect.
This, precisely, is analogical production: creating a new form (twote) by extending a contrast seen in other words (yeet/yote). Analogy is a central topic in my research. I have been trying to answer questions such as: How do we decide what form to use ? How difficult is it to guess? How does this contribute to language change?
But first, have you answered the poll?
Here at the SMG we need to know: What do you think the past tense of 'I tweet' is?
To investigate further why we would say twote rather than tweeted, I took out my PhD software (Qumin). Based on 6064 examples of English verbs1, I asked Qumin to produce and rank possible past forms of tweet2. To do so, it read through examples to construct analogical rules (I call them patterns), then evaluated the probability of each rule among the words which sound like tweet.
Qumin found four options3: tweeted (/twiːtɪd/), by analogy with 32 similar words, such as greet/greeted; twet (/twɛt/), by analogy with words like meet/met; tweet (/twiːt/) by analogy with words like beat/beat, finally twote (/twəˑʊt/), by analogy with yeet. Figure 1 provides their ranking (in ascending order) according to Qumin, with the associated probabilities.
Figure 1. Qumin’s ranking of the probability for potential past forms of to tweet
As we can see, Qumin finds twote to be the least likely solution. This is a reasonable position overall (indeed, tweeted is the regular form), so why would both the official Twitter account and many Twitter users (including several linguists) prefer twote to tweeted?
But Qumin has no idea what is cool, a factor which makes yeet/yote (already a slang word, used on the internet) a particularly appealing choice. Moreover, Qumin has no access to semantic similarity, which could also play a role. Verbs that have similar meanings can be preferred as support for the analogy. In the current case, both speak/spoke and write/wrote have similar pasts to twote, which might help make it sound acceptable. Some speakers seem to be aware of these factors, as seen in the tweet above.
Is it twankt or twunkt? I'm thinking about the past-tense of tweet.
Are most speakers aware of the variant twote and using it? Before concluding that the model is mistaken, we need to observe what speakers actually use. Indeed, only usage truly determines “what is the past of tweet”. For this, I turn to (automatically) sifting through Twitter data.
A few problems: first, the form “tweet” is also a noun, and identical to the present tense of the verb. Second, “twet” is attested (sometimes as “twett”), but mostly as a synonym for the noun “tweet” (often in a playful “lolcat” style), or as a present verbal form, with a few exceptions, usually of a meta nature (see tweets below). I couldn’t find a way to automatically distinguish these from past forms while also managing within the Twitter API limits. Thus, I left out both from the search entirely. This leaves only our two main contestants.
If it's not already been formally done, I should now like to declare the past tense of "tweet" to be "twet"
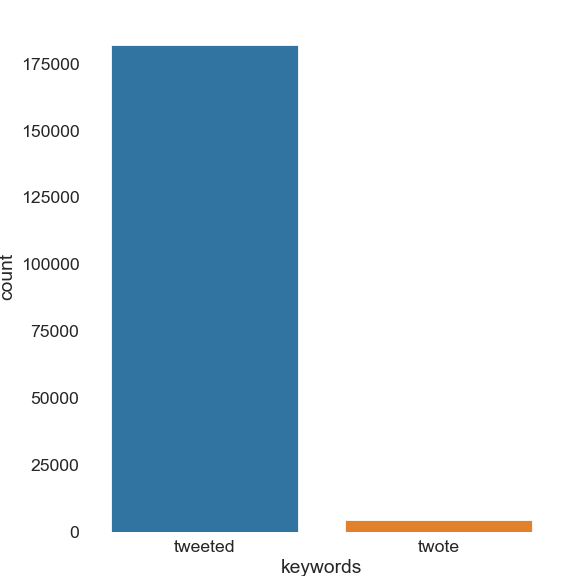
I extracted as many recent tweets containing tweeted or twote as Twitter would let me — around 300 000 tweets twotten between the 26th of August and the 3rd of September. 186777 tweets remained after refining the search4. Of these, less than 5000 contain twote:
Counts of tweets containing either of two possible pasts for the verb “to tweet” in the past few days on twitter (mentions excluded).
As you can see, the tweeted bar completely dwarfs the other one. However amusing and fitting twote may be, and despite @Twitter’s prescription (but conforming with Qumin’s prediction), the regular past form is by far the most used, even on the platform itself, which lends itself to playful and impactful statements. This easily closes this particular English Past Tense Debate. If only it were always this simple!
The English verb data I used includes only the present and past tenses, and is derived from the CELEX 2 dataset, as used in my PhD dissertation and manually supplemented by the forms for “yeet”. The CELEX2 dataset is commercial, and I can not distribute it. [↩]
The code I used for this blog post is available here, but not the dataset itself. Note that for scientific reasons I won’t discuss here, this software works on sounds, not orthography. [↩]
One last possibility has been ignored by this polite software, a form which follows the pattern of sit/sat. I see it used from time to time for its comic effect, but it does not seem at all frequent enough to be a real contestant (and I do not recommend searching this keyword on Twitter). [↩]
Since there has been a lot of discussion on the correct form, I exclude all clear cases of mentions. I count as mentions any occurrences wrapped in quotations, co-occurring with alternate forms, mentioning past tense, or with a hashtag. Moreover, with the forms in –ed, it is likely that the past participle would be identical, but for twote, the past participle could well be twotten. To reduce the bias due to the presence of more past participles in the usage of tweeted, I also exclude all contexts where the word is preceded by the auxiliary forms has, have, had, is, are, was, were, possibly separated by an adverb. [↩]
Careful who you climb a tree near: Respect and taboo in Vanuatu
One humid afternoon, during breadfruit season in North Ambrym, my language teacher, Isaiah, and I were on the lookout for some ripe breadfruit to roast for lunch. Our path led past his nephew, George’s, house. Isaiah saw some ripe breadfruit in the tree next to where George was sitting on his veranda. Isaiah wanted to get the breadfruit, but said that because George was there, he couldn’t, and we would have to find some others instead. I asked if it was George’s breadfruit tree, and that’s why he didn’t want to take it when George was around. Isaiah said no; rather, the problem was if we went up the tree when George was underneath, then he would have to pay a small fine to George. Over a lunch of roasted and pounded breadfruit called wuwu, Isaiah explained further. It was to do with respect and taboo.
Respect in language takes many forms. There is the tu/vous distinction in French, where tu is the informal form of ‘you (singular)’ and is used with friends and those younger than you, whereas vous ‘you (plural)’ is formal and is used with those elder or senior than you and for people you don’t know. Similar distinctions are found with the German du/Sie. English doesn’t have a grammatical distinction in politeness like this, but uses different sentence structures to express politeness: compare pass me the salt please with could you please pass me the salt, or the even more polite would you be so kind as to pass me the salt please.
Now let’s get back to eating that heavy sticky coconut-cream-slathered wuwu with Isaiah. He told me that you must respect certain members of your extended family by showing physical politeness. Respect is translated as tengnean in the language of North Ambrym. The people who you must respect are your taboo family, described by the verb gorrne. Respect for your taboo family on Ambrym is realised in different ways – through physical restrictions and through language. The family members who command the most respect are your sister’s son or your husband’s brother.
The physical restrictions with a taboo relative include:
You can’t eat in front of them
You can’t joke with them
You can’t climb over them, or be physically higher than them
You can’t sleep in front of them
You can’t enter their house
But what about restrictions on language? The normal translation of ‘hello’ in North Ambrym would be neng le, which literally means ‘you there’, using neng, the singular form of ‘you’. But you are not allowed to say this to your taboo relatives. Instead, you must say gōmōro le using the dual form of ‘you’, meaning ‘you two there’, even though you are addressing one person. This is similar to French or German mentioned earlier. However, North Ambrym, like many Oceanic languages, not only has singular and dual, but also paucal, meaning ‘a few’, and plural pronouns. Of these possibilities, the dual is used for respect, not the plural as in French or German.
Respect is not confined to pronouns such as ‘you’; people also have to avoid using certain words in front of their taboo relatives. For example, if your sister’s son came, and you invited him to sit down and have some food, you would have to avoid certain verbs, such as taa ‘sit’ or ngene ‘eat’. You would use lingi ‘put’ instead of ‘sit’ and tewene ‘make’ instead of ‘eat’ so the whole sentence would be rephrased as ‘you-two come and put your-dual-self here and make the food’.
You must also avoid certain words concerning body parts, specifically words relating to parts of the head. Normally when talking about body parts in North Ambrym you would use a bound noun – a type of noun which specifies who owns the body part – so the word for ‘tooth’ would be lowo-n ‘his/her tooth’, lowo-m ‘your tooth’, or lowo-ng ‘my tooth’. The end of the noun (-n/-m/-ng in this example) indicates whose tooth it is. But these words are not allowed when talking in front of your taboo relatives. Instead, you could use a free form of the noun, such as leo ‘tooth’.
Another avoidance strategy is to change a verb to a noun using a special nominalising prefix a- that appears on the beginning of the word and turns it into a noun. The verb itself is also reduplicated. For example, the verb ta ‘cut’ can be turned into a noun atata ‘tooth’ (literally ‘thing for cutting’).
Finally, a more idiomatic expression could be used; in this case, tooth is replaced by tō which literally translates as ‘limpet shell (traditionally used as a vegetable grater)’ or teye ‘clam shell/axe’ as a way of avoiding the bound form for ‘tooth’.
Here’s a handy table to help you get your head (or just head!) around avoiding the bound forms.
Bound
Free
Nominalisation
Idiomatic
rralnye-n ‘his, her ear’
teleng ‘ear’
arorongta ‘thing for listening, headphones’
harrlengleng ‘listening’
lowon ‘his, her tooth’
leo ‘tooth’
atata ‘thing for cutting’
tō ‘limpet shell (used as a grater)’
teye ‘clam shell, axe’
metan ‘his, her eye’
marr ‘eye’
ateter ‘thing for seeing, glasses’
hal ‘road, path’
glas ‘glasses’
guhun ‘his, her nose’
kuu ‘nose’
akunuknuu ‘thing for smelling’
woulun ‘his, her hair’
wovyul ‘hair’
ōrr ge mre ‘place which is above’
As time passes, so do traditions, and the older generations mourn the loss of respecting their taboo relatives. They complain that younger generations now joke with their taboo relatives or put their arms around them. This art of speaking is being lost and the physical taboos are being eroded. However, this change is not new and has been going on for several generations. Some of the more extreme forms of respect are almost out of living memory. One of the village elders, Ephraim, recounted a memory of seeing how his grandmother, Mataran, displayed respect when returning from the garden, with her vegetables one day. When she approached her home, she saw that one of her husband’s brothers was there. She came close, then crawled the rest of the way past her husband’s brother with her basket of vegetables over her shoulder, until she was in her doorway before standing up again.
So the next time you are in Vanuatu, take care when climbing trees and make sure you know which of your relatives are nearby!
As the University of Surrey’s foremost (and indeed only) blog about languages and how they change, MORPH is enjoyed by literally dozens of avid readers from all over the world. But so far these multitudes have not received an answer to the one big linguistic question besetting modern society. Namely, what on earth is going on with the name of the plant that British English calls the aubergine, but that in other times and places has been called eggplant, melongene, brown-jolly, mad-apple, and so much more? Where do all these weird names come from?
I think the time has finally come to put everyone’s mind at rest. Aubergines may not seem particularly eggy, melonish, jolly or mad, but lots of the apparently diverse and whimsical terms for them used in English and other languages are actually connected – and in trying to understand how, we can get some insight about how vocabulary spreads and develops over time. It turns out that one powerful impulse behind language change is the fact that speakers like to ‘make sense’ of things that do not inherently make sense. What do I mean by that? Stay tuned to find out.
To get one not-so-linguistic point out of the way first, there is no real mystery about eggplant (the word generally used in the US and some other English-speaking countries, dating back to the 18th century), which is not linked to anything else I am talking about here. It is hard to imagine mistaking the large, purple fruit in the photo above for any kind of egg, but that is not the only kind of aubergine in existence. There are cultivars with a much more oval shape, and even ones with white rather than purple skin: pictures like this, showing an imposter alongside some real eggs, make it obvious how the word eggplant was able to catch on.
Meanwhile, aubergine, which is borrowed from French as you might expect, has a much more complex history, and can be traced back over many centuries, hopping from language to language with minor adjustments along the way. The plant is not native to the US, Britain or France, but to southern or eastern Asia, and investigating the history of the word will eventually take us back in the right geographical direction. Aubergine got into French from the Catalan albergínia, whose first syllable gives us a clue as to where we should look next: as in many al- words in the Iberian peninsula (e.g. Spanish algodón ‘cotton’), it reflects the Arabic definite article. So, along with medieval Spanish alberengena, the Catalan item is from Arabic al-bādhinjān ‘the aubergine’, where only the bādhinjān bit will be relevant from here on. This connection makes sense, because the Arab conquest had such an impact on the history of Iberia. And more generally, we have the Arabs to thank for the spread of aubergine cultivation into the West, and also – indirectly – for this charming illustration in a 14th-century Latin translation of an Arabic health manual:
Page from the 14th c. Tacuinum Sanitatis (Vienna), SN2644
But bādhinjān is not Arabic in origin either: it was borrowed into Arabic from its neighbour, Persian. In turn, Persian bādenjān is a borrowing from Sanskrit vātiṅgaṇa… and Sanskrit itself got this from some other language of India, probably belonging to the unrelated Dravidian family. The word for aubergine in Tamil, vaṟutuṇai, is an example of how the word developed inside Dravidian itself.
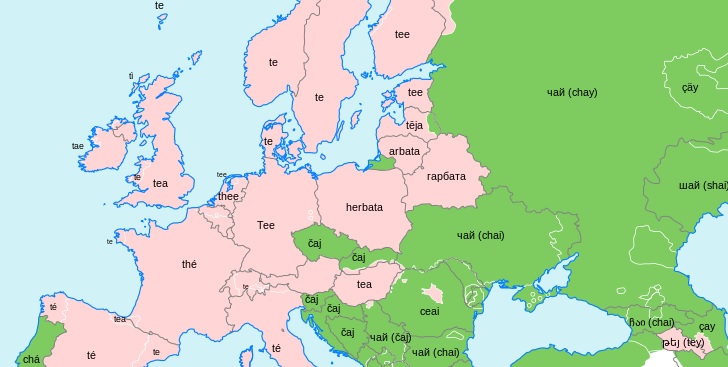
That is as far back as we are able to trace the word. But the journey has already been quite convoluted. To recap, a Dravidian item was borrowed into Sanskrit, from there into Persian, from there into Arabic, from there into Catalan, from there into French, and from there into English – and in the course of that process, it managed to go from something along the lines of vaṟutuṇai to the very different aubergine, although the individual changes were not drastic at any stage. The whole thing illustrates how developments in language can go with cultural change, in that words sometimes spread together with the things they refer to. In the same way, tea reached Europe via two routes originating in different Chinese dialect zones, and that is what gave rise to the split between ‘tea’-type and ‘chai’-type words in European languages:
[Map created by Wikimedia user Poulpy, licensed CC BY-SA 3.0, cropped for use here]This still leaves a lot of aubergine words unaccounted for. But now that we have played the tape backwards all the way from aubergine back to something-like-vaṟutuṇai, we can run it forwards again, and see what different historical paths we could follow instead. For example, Arabic had an influence all over the Mediterranean, and so it is no surprise to see that about a thousand years ago, versions of bādhinjān start appearing in Greece as well as Iberia. Greek words could not begin with b- at the time, so what we see instead are things like matizanion and melintzana, and melitzana is the Greek for aubergine to this day. There is no good pronunciation-based reason for the Greek word to have ended up beginning with mel-, but what must have happened is that faced with this foreign string of sounds, speakers thought it would be sensible for it to sound more like melanos ‘dark, black’, to match its appearance. That is, they injected a bit of meaning into what was originally just an arbitrary label.
Meanwhile the word turns up in medieval Latin as melongena (giving the antiquated English melongene) and in Italian as melanzana, and a similar thing happened: here mel- has nothing to do with the dark colour of the fruit, but it did remind speakers of the word for ‘apple’, mela. We know this because melanzana was subsequently reinterpreted as the expression mela insana, ‘insane apple’. To produce this interpretation, it must have helped that the aubergine (like the equally suspicious tomato) belongs to the ‘deadly’ nightshade family, whose traditional European representatives are famously toxic. So, again, something that was originally just a word, with no deeper meaning inside, was reimagined so that it ‘made sense’. As a direct translation, English started calling the aubergine a mad-apple in the 1500s.
Poster from a 16th c. aubergine factory
There are many more developments we could trace. For example, I have not talked at all about the branch of this aubergine ‘tree’ that entered the Ottoman Empire and from there spread widely across Europe and Asia. But instead I will return now to the Arab conquest of Iberia. This brought bādhinjān into Portuguese in the form beringela, and then when the Portuguese started making conquests of their own, versions of beringela appeared around the world. Notably, briñjal was borrowed into Gujarati and brinjal into Indian English, meaning that something-like-vaṟutuṇai ultimately came full circle, returning in this heavy disguise to its ancestral home of India. And to end on a particularly happy note, when the same form brinjal reached the Caribbean, English speakers there saw their own opportunity to ‘make sense’ of it – this time by adapting it into brown-jolly.
Brown-jolly is pretty close to the mark in terms of colour, and it is much better marketing than mela insana. But from the linguist’s point of view, they both reinforce a point which has often been made: speakers are always alive to the possibility that the expressions they use are not just arbitrary, but can be analysed, even if that means coming up with new meanings which were not originally there. To illustrate the power of ‘folk etymology’ of this kind, linguists traditionally turn to the word asparagus, reinterpreted in some varieties of English as sparrow-grass. But perhaps it is time for us to give the brown-jolly its moment in the sun.
You have very certainly heard about Wordle, the viral word game by powerlanguage, recently bought by the NYT. In the original game, a 5-letter English word is secretly chosen every day, which players attempt to guess in 6 tries. Each guess is answered by colored cues: green for “correct letter in the correct place”, orange for “correct letter in the wrong place”, gray for “incorrect letter”. The concept of wordle is not new, and resembles games such as Jotto, Lingo, and mastermind.
A sample game of Mastermind.
While some may have been annoyed by the endless stream of three-color square emojis reporting players’ success and inundating social media I have been delighted by the productivity displayed by the many variants: in hello wordl, play an endless number of games; in dordle, quordle, octodle guess several words at once; in squardle, play in two dimensions; in nerdle, guess a mathematical formula; in absurdle, the games does its best to get away from your guesses, etc.
Quordle lets you play 4 games at once
Some derived games transform the game mechanics, but the simplest variation is to switch the vocabulary (have you tried queerdle or lordle of the rings?) or the language. Indeed, wikipedia already references more than 40 wordle language variants. If I believe my social feeds, many linguists have found that they were able to play in languages that they didn’t speak, provided that they had some intuitions of the phonotactics and orthographic sequences. I was however quite disappointed to see that many versions retained the English-centric 1-letter:1-unicode-character, and avoided diacritics altogether, leading to strange impoverished typography — this is the case for example of the French wordle, “le mot”.
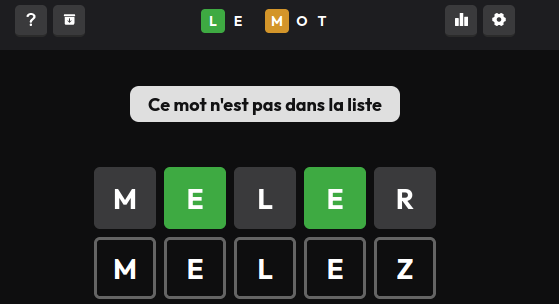
The French wordle accepts “meler”, but not “melez”
While playing variants, I realized that a wordle is only as good as its word list: some games rely on lexicons which contain only citation forms (infinitives for French verbs) and exclude the many others inflected forms, leading to a frustrating game experience. For example, in Le Mot, one can play mêler (or more exactly, meler) “to mix”, but not meles “(you) mix”. It happens that well curated words lists including inflected variant is a Surrey Morphology Group specialty: lexicons and dictionaries are a common product of language documentation, and as its names indicates, researchers at the SMG have a particular focus on morphology. We have been maintaining open inflectional databases since the 90s. After discussion, we agreed collectively to start by producing two wordle-like games, corresponding to the two main lexicons in the SMG databases, respectively the Dictionary of Archi and the Nuer Lexicon.
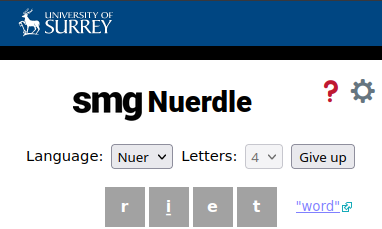
The Nuer language, or Thok Nath, is a West Nilotic language spoken by approximately 900,000 to two million people in South Sudan and Ethiopia, as well as in diaspora communities throughout the world. The SMG has created an interactive online dictionary for it. From this lexicon, I have extracted 6218 words, mostly verbs and nouns, with a few other part of speech represented. All targets are taken from this set of words. However, using only the lexicon would risk rejecting a lot of words the speakers might know, even though they are not documented in the lexicon. Thus, I also extracted all of the words from the Nuer translation of the Bible1. This led to a total lexicon of 13476 words2.
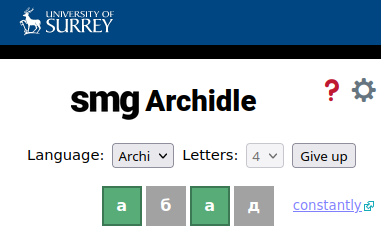
Archi is a Daghestanian language of the Lezgic group spoken by about 1200 people in Daghestan. At the SMG, we created a dictionary of Archi, with entries in Russian, English, and Nuer (both orthographic and phonetic forms), from which I extracted 3626 words for our wordle puzzle. For now, we do not have any more words for Archi, but we are working on it. In the game, we have ignored the stress diacritics, which might not be intuitive enough for speakers.
Nuer keyboards: from a mobile app (left), or from our wordle game (right).
In order to create the SMG wordles, I started from the open source code of the re-playable version, hello wordle. In order to keep the game closer to its original, I removed the re-playable function. However, I did keep the option to play a range of word length from 4 to 7 letters. Each day, you can thus play 4 games in each language. A main challenge was that the Nuer orthography comprises diacritics, which required rewriting large parts of the game, as it previously assumed that each letter could be written with a single character. Another difficulty came from the fact that neither language has a unique, widely used, keyboard layout. For Nuer, we created one based on a mobile keyboard, which we extended to include more diacritics.
Cyrillic keyboards: Russian keyboard from a mobile app (left), or Archi keyboard from our wordle game (right).
In both cases, we strove to make the game playable by learners, linguists, and curious people who do not speak Archi or Nuer. For this reason, we made the default word length 4 letters rather than 5, to make the game easier. Moreover, we added short English definitions for all words in our lexicons, with links to their full definitions in our resources. Words in Nuer from the bible are not always present in our Nuer lexicon, and hence, some words in Nuer can appear without translations. Finally, in order to help beginners get started, we provide a few example words of the correct length each day, hidden by default, which can be used to start playing.
A word played in Nuerdle, with translation in the margin
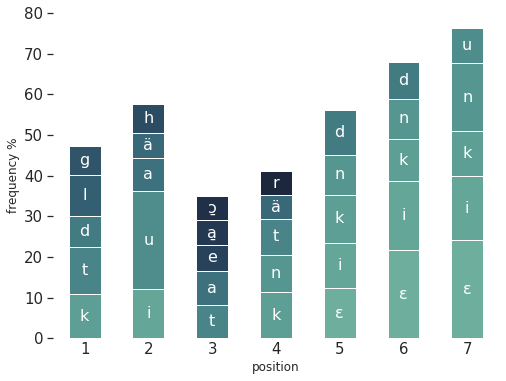
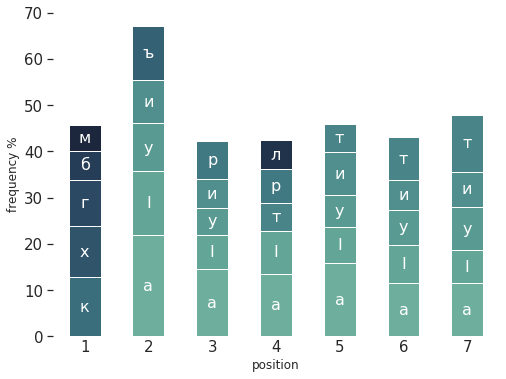
Besides learning the languages, scouring the dictionary, or using the words given as hints daily, how can you get better at the Nuer or Archi wordle ? It helps to pay attention to the frequency of each letters, and try to play words with frequent letters, in order to reduce the pool of potential words quickly. For the English wordle, some have calculated the optimal starting word. Rather than risk spoiling the game, I provide below the relative frequencies of each of the 5 most frequent letters, for each position (1 to 7) in Nuerdle and Archidle words. This should give an idea of frequent letters at each position. The colors are assigned according to overall frequency in the lexicon, with light greens more frequent than dark blues. Each bar represents the frequencies of the five most frequent letters in a word position (from 1 to 7), ignoring the other, less frequent letters. Each stacked colored bar’s height, between two white lines, represents the letter’s frequency: eg. in Nuer, a word in our lexicon starts with k around 10% of the time, and with t around 12% of the time. If there is some interest, a future blog post could explore further the frequent sequences and letter patterns in either languages.
Frequency of each character in Nuer words in our lexicon, per positonFrequency of each character in Archi words in our lexicon, per positon
Finally, since this is a morphology blog, I would like to draw your attention to the interesting way in which English acquired a new -dle suffix. The original game is called wordle, a combination of the creator’s last name Wardle, and of word. As the game became viral, the apparent suffix has come to mean “game in the wordle family” (or maybe “online guessing game”). Interestingly, even though the most obvious decomposition of wordle seems to be word+le, the productive suffix is -dle, not -le. Could this be because the family resemblance in the new words is more obvious by keeping more common material ? Isn’t analogy mysterious? In any cases, after hesitating with ri̱etle (from ri̱et “word”+le, in Nuer) and č’atle (from č’at, “word” in Archi), we settled instead on calling our games Archidle and Nuerdle.
excluding words starting with a capital, in order to avoid proper names. [↩]
Recently, a friend of mine received an email saying that because of their hard work in difficult circumstances this year, he and his colleagues would all be “gifted” a few extra days off over Christmas. And the other day I saw someone else wondering on Facebook: ‘when did the word “given” cease to exist, and why is everything “gifted” now?’ So with the festive season fast approaching, it seems like a good time to ask: is there really something funny going on with the word gift?
Once you gift it a bit of thought, I don’t think I am gifting anything away by pointing out that the verb to give is still very much with us. But the rise of a rival verb to gift, in some contexts where you’d expect to give, has been receiving attention for a while now: in recent years it has been discussed on National Public Radio in the US (The Season of Gifting) and in The Atlantic magazine (‘Gift’ is Not a Verb). Whether or not it bothers you personally, you may well have noticed the trend. The existence of gift as a noun is just a mundane fact of life, but apparently the corresponding verb gets people talking.
Gifted children
Now, nobody would be surprised to learn that English changes over time, or even that it has pairs of words that mean more or less the same thing… how much difference is there between liberty and freedom, or between little and small? And in fact, synonyms have an important role to play in language change. If we look back and notice that one expression has been replaced by another – a historical change in the vocabulary, as when the Shakespearian anon gave way to at once – then there must have been an intervening period when they were both around with pretty much the same meaning, and people had a choice of which one to use.
Does that mean that we do now find ourselves in the very early stages of a long historical process which will eventually result in to gift replacing to give altogether? If that’s the case, in a few generations’ time people will be saying things like ‘Never gift up!’ or ‘Could you gift me a hand?’.
Frankly, my dear, I don’t gift a damn
But whatever happens in the future, that clearly isn’t the situation now. So if English often provides multiple ways of saying the same thing, why have people taken the coexistence of to give and to gift as something to get worked up about – and can linguistics shed any light on what is going on here?
One thing that makes this specific pairing stand out is that the two words are just so similar. Gift is obviously connected with give in the first place: that makes it easy to wonder why anyone would bother to avoid the obvious word, only to pick an almost identical one. Another factor (as the title of The Atlantic article makes clear) is the idea that gift is really a noun, and so people shouldn’t go around using it as a verb.
But if we take a broader view, it turns out that what is happening with to gift is not out of the ordinary. Instead, it fits neatly with some things that linguists have already noticed about English and about language change more generally. For one thing, English is very good at ‘using nouns as verbs’ – which is why we can hammer (verb) with a hammer (noun), fish (verb) for fish (noun), and so on. So a verb gift, meaning ‘give as a gift’, goes well with what the language already does. What often happens is that when a new verb of this kind starts to take off, not all speakers are happy about it, but after a while it gains acceptance. For example, the twentieth century saw complaints about verbs-from-nouns such as to host, to access or to showcase, but they grate less on people nowadays.
You could even try hammering with a fish!
Ultimately, the ability to create words like this is just an ‘accidental’ fact about English, which also has various other ways of making verbs from nouns – for example, turning X into ‘X-ify’ (person-ify, object-ify) or ‘be-X’ (be-friend, be-witch). The bigger question may be: as we already have the verb give, why would anyone bother to make a verb gift in the first place, and why would it ever catch on? It might seem that by definition, a gift is something you give, so inventing a term meaning ‘give as a gift’ is pointless.
But that is not how things really are. Gifts are given, but that doesn’t mean that everything that can be given counts as a gift: a traffic warden might give you a parking ticket and in return you might give him a piece of your mind, but the noun gift doesn’t cover either of those things. Among other restrictions on its use, it is generally associated with positive feelings: if you give something as a gift, it is usually something tangible that you expect to be warmly received, and that carries over into the verb to gift itself.
This subtle difference between to give and to gift explains why for the moment it is impossible to gift someone a sidelong glance, or lots of extra work to do. But apparently it is becoming possible to gift an employee some time off, even though that is not a physical present that can be handed over and unwrapped. Evidently, the writer just felt like using a verb that sounded a bit more interesting and positive than to give, and the ‘warmly received’ part of the meaning was enough to outweigh the lack of any tangible object involved.
This is an example of something that happens all the time in language change. Naturally, while a word is still restricted in its use, it is more noticeable and interesting than a word you hear regularly. As a result, sometimes people decide to go for the less common word even where it doesn’t quite belong, to achieve some kind of extra effect… but over time, this process makes the word sound less and less special, until it eventually becomes the new normal. We don’t even need to look far to find this happening precisely to the word ‘gift’ in other languages: French donner ‘give’ is based on don ‘gift’, and it has totally wiped out the normal verb for give that ‘should’ have been inherited from Latin.
So if speakers and writers of English continue to chip away at the restrictions on gift as a verb, maybe one day it really will replace give altogether. Of course, that idea sounds totally outlandish at the moment – but then, I’m sure the ancient Romans would have thought much the same thing. You never know what will happen next: language change truly is the gift that keeps on giving!
What slips of the tongue can tell us about language
“The grouchy knight cuddled the rowdy seer’s adorable puppy while devouring lasagne”
This is probably a sentence you’ve never heard – or produced – before. Yet this experience is not novel – everyday, you make utterances you’ve never heard, and understand new ones.
Producing such utterances is not a trivial matter. To do this we have to generate them – that is, decide on the concept to be expressed, encode that into words and structures, then into the sounds that make up our words before sending instructions to our articulatory apparatus to produce the utterance. All within fractions of a second.
Yet, sometimes we make mistakes, and produce things we didn’t intend to do:
Error (The Mistake we Make)
Target (What we had intended to say)
heft lemisphere
left hemisphere
squoor
squeaky floor
a leading list
a reading list
gave the goy
gave the boy
stough competition
stiff/tough competition
she sliced the knife with a salami
she sliced the salami with a knife
a hole full of floors
a floor full of holes
We usually notice these errors when we make them and correct ourselves. But rather than being merely slips of tongue, they are a goldmine of information as they demonstrate breakdowns at various parts in the speech production process.
Some of these errors are lexical selection errors – we select the wrong lexical concept or lemma for the message we’re trying to say. That is, we select the wrong word stored in our brains, we pick the wrong word from our mental dictionary. This can be simply the wrong concept, as in: ‘he’s carrying a bag of cherries’ instead of ‘grapes’. Sometimes, we can combine words together in blends: ‘the competition is getting a little stough’ instead of stiff or tough. Other times, we can exchange words within a sentence, as in ‘she sliced the knife with a salami’, rather than ‘she sliced the salami with a knife’.
We can also make phonological errors, that is, errors in the sound structure of our words:
Exchanges
heft lemisphere
left hemisphere
fleaky squoor
squeaky floor
cheek and ch[ɔː]se
Chalk and cheese
Additions
enjoyding it
enjoying it
Deletions
cumsily
Clumsily
Anticipations
leading list
reading list
Perseverations
gave the goy
gave the boy
We can look at large data sets, or corpora, to see what kinds of errors are commonly made. We find that these errors are still well-formed in terms of their sound structure, or phonology. 60-90% of errors (depending on the corpus you look at) involve errors with a single sound or segment, and these errors are sensitive to syllable structure. That is, we might swap segments from the same part of the syllable as in exchanges:
face spood <space food
Or we might combine the beginning of one syllable and the end of another:
grool < great + cool
We also like to swap sounds that are similar to each other, so
paid mossible < made possible
is more likely than
two sen pet < two pen set
There are exceptions to these generalisations of course – but they are rare.
Speech errors give us an insight into normal speech production processes. The fact that sound errors occur at all tells us that speech production is a generative process – it is not that we just reproduce fully formed stored sentences, but rather we create each utterance afresh each time. In order to mix or swap two elements, both must be activated at the same point of the production process.
Furthermore, the range of speech across which errors can occur implies that the span of processing is greater than a single word. You might be familiar with spoonerisms, popularised by Dr William Archibald Spooner:
You were caught fighting a liar in the quad < You were caught lighting a fire in the quad
You have hissed my mystery lectures < You have missed my history lectures
You have tasted the whole worm < You have wasted the whole term
We must plan more than a word ahead for errors like these to happen.
There is a much wider array of questions we can ask about speech production than can be answered by speech errors, but certainly they are an entertaining place to start.