“Are potatoes ‘badder’ than usual in the UK atm?” This was the question posed by a reddit user last week. Despite the scare quotes, this use of the word ‘badder’ was met with general mockery (as well as some genuine attempts to answer the question: the wet weather has caused poor growing conditions for root veg this year, if you were wondering). Yet the intended meaning is completely clear to English speakers; more so than if it had been phrased ‘are potatoes worse than usual?’.
In fact, ‘badder’ has seen a big increase in use since the mid 20th century (although it’s been around for a long time, and was even used by Chaucer). Google books offers numerous titles from recent years such as Bigger and badder: a billionaire romance (2016), How to be a badder bitch (2018) and the Bad guys even badder box (2019). What these titles have in common is that ‘bad’ is used with a special meaning as part of a set phrase. ‘Bad guy’ evokes a stock villain from a story, not just any old guy who happens to be bad. A ‘bad bitch’ is a tough, empowered woman. Thus a ‘badder guy’ is even more villainous, and a ‘badder bitch’ is even cooler and tougher. ‘Can you imagine a worse bitch than Helen?’ makes it crystal clear that the speaker doesn’t like Helen, but ‘can you imagine a badder bitch than Helen?’ implies admiration instead.
These are examples of what linguists call lexicalisation. ‘Bad guy’ and ‘bad bitch’ have become set phrases whose meaning is more than just the sum of their individual parts. In other words, the meaning of ‘bad guy’ is not just the meaning of ‘bad’ + ‘guy’, and would have to be listed as a separate entry in a dictionary. In a sense, it behaves as a single word (which is also betrayed by its special stress pattern: a bad guy is a guy who is bad, while a bad guy is a villain). This is even clearer for ‘bad bitch’: both bitch and bad have strongly negative connotations, but bad bitch is positive.
The coinage of ‘badder bitch’ reveals a change that has already happened under the surface. Two words have become one phrase, with its own unpredictable meaning. Bad and worse are forms of the same lexeme, in the sense that they’d be listed under the same dictionary entry: they are members of the same paradigm. ‘Badder bitch’ shows that changes in meaning can happen to individual forms in the paradigm, rather than lexemes, otherwise ‘worse bitch’ would automatically take on the meaning of ‘bad bitch’. Bad in the newly lexicalised bad bitch starts off its life without any comparative form, so you’ve got to make up something new if you want to use one.
Something similar can be seen in examples like straight or wrought, which started off life as past participles of the verbs stretch and work. Straight in a sentence like ‘I have straight the string’ was regularised to stretched, and wrought to worked. But the forms straight and wrought were left behind in usages like ‘the straight string’ or ‘the wrought iron’, revealing that they had become lexicalised as adjectives in their own right.
Back to badder potatoes. Bad in the context ‘a bad potato/apple/egg (etc.)’ has a special sense of ‘rotten’ that is somewhat lexicalised, hence ‘badder potatoes’ are more rotten, while ‘worse potatoes’ could be worse in any number of ways. Either that, or potatoes are becoming meaner and more villainous as a result of the miserable weather, which frankly I can relate to. Let’s remain vigilant, just in case.
A villainous potato coming to get you, courtesy of https://hotpot.ai/art-generator
When you want to look up a word, how do you go about it? The dictionary is organised by the first letter of the word, so that is what you consider first. And when you want to compare languages, what is the first thing to catch your eye? Again, the first sound. Thus, when looking at a set of words like English fish, father, full, Latin piscis, pater, plenus and Scottish Gaelic iasg, athair, làn, the fact that f- in English corresponds to p- in Latin and zero in Scottish Gaelic spring immediately to our attention, reading as we do from left to right.
Thus, we might presume that the beginning of a word is somehow especially stable, and that sounds which appear at the beginning of a word are a good first indicator of etymology. However, in fact the beginning of a word is not so immutable as you might suppose. Famously, Celtic languages have initial consonant mutations, which alters the initial consonant of a word in regular ways depending on grammatical context. So in Welsh, while ‘Wales’ is Cymru, ‘Welcome to Wales’ is Croeso i Gymru, ‘in Wales’ is yng Nghymru and ‘England and Wales’ is Lloegr a Chymru. This is interesting enough, but not the only way that the start of a word may be altered in languages. Indeed, we don’t even have to leave English to find examples of a different phenomenon that can take place in the history of an individual word.
Let us take a word like adder (the snake specifically, not someone that does addition!). We can look for cognates in closely-related languages, but we are immediately presented with a problem: German Natter, Frisian njirre and Icelandic naðra all seem like they should be related (all being words for ‘snake’), but what’s with this n- at the beginning of the word? Things only get more confusing when we notice words like Latin natrix ‘watersnake’, Welsh neidr or Scottish Gaelic nathair, all again showing an n-. Finally, when we look at Old English we find that the word there is næddre! What’s going on? We know that in general English n- doesn’t do anything particularly strange and it certainly doesn’t just disappear from the beginnings of words, as evidenced by numerous forms like name, night, nest, new, and nine which have had an n- since Proto-Indo-European!
The answer lies in a phenomenon that linguists call ‘rebracketing’. This is a fairly straightforward notion; linguists already make use of brackets to show the internal structure of phrases, thus any change in the structure of the phrase is notated by a change in the arrangement of the brackets. (It will be noted that some authors, including the Oxford English Dictionary, use the term metanalysis instead, but the meaning is the same.)
In the case of adder, the confusion comes from the indefinite article, which in English is a before words beginning with a consonant and an before words beginning with a vowel. Thus, if a word begins with an n-, this can find itself being rebracketed onto the indefinite article: thus [a [nadder]] becomes [a-n [adder]]. And this isn’t the only word where this has happened in English either: thus [a [napron]] (from French napperon) became [a-n [apron]]. On the flipside, the opposite is also found, where the -n from the indefinite article finds itself attached to the front of a word that originally began with a vowel, e.g. [an [ewt]] → [a [n-ewt]] or [an [ekename]] → [a [n-ickname]].
An ewt!
Some of these forms have since become the predominant forms of their respective words, but such is not always the case. For example, uncle derives from a French word oncle, ultimately from Latin avunculus. However, those who are familiar with their Shakespeare will remember the Fool in King Lear, who refers to the title character as ‘nuncle’. Here the reanalysis, rather than from the indefinite article, seems to have been on the basis of possessive pronouns mine and thine, which are particularly frequently used with kind terms: thus [mine [uncle]] becomes [my [nuncle]]. Yet, unlike with the other examples, this has not stuck around, perhaps because the other possessive pronouns (his, her, our, your, their) which would not have motivated this reanalysis; thus the original uncle stuck around and was able to reassert itself.
Nor is English alone in exhibiting these kinds of change. In the adder~nadder case, the same reanalysis has also taken place in Dutch and Low German, also spelt adder in both cases. Similarly, Arabic nāranj was borrowed into Spanish as Naranja, but this underwent rebracketing when it was borrowed into Italian as arancia, and it was from there that the word spread to the rest of Europe, including English orange.
French provides us with an especially interesting example of layered reanalyses in a single word. In Old French, unicorne was reanalysed as beginning with the indefinite article (which is in a sense not incorrect: the literal meaning of the word is ‘one-horn’ and ‘one’ is the source of the French indefinite article, as well as indefinite articles in general cross-linguistically). This left a form icorne, which would contract with the definite article, giving l’icorne ‘the unicorn’. However, at some point, this contracted form with the article came to be reanalysed as the base of the noun itself, with the result that licorne is now simply the French for ‘unicorn’, leading to constructions such as la licorne ‘the unicorn’ where a historical definite article appears ‘doubled up’!
Some of the most complex cases of rebracketing can be found in Scottish Gaelic. Here we have a number of potential sources of rebracketing, both because the definite article changes depending on the following noun and because of the interaction of the definite article and the mutation system.
Firstly, with vowel-initial masculine noun the definite article prefixes a t- e.g. eun ‘bird’ but an t-eun ‘the bird’. Unsurprisingly, based on the examples we have seen above, this prefixed t- has in many cases become attached to the noun. Interestingly this is particularly common in loanwords from Old Norse, such as talla ‘hall’ from hǫll, tòb ‘small bay’ from hóp (òb is also common) and tolm ‘small islet’ from holmr, as well as other loans such as taigeis ‘haggis’ and tobha ‘hoe’ from English.
In a similar vein, one of the components of consonant mutation is Scottish Gaelic is that an f sound disappears (though is still written as fh). As a result, a larger number of words that began with vowels in Old Irish have acquired an f- in Scottish Gaelic, e.g. áinne ‘ring’, uar ‘cold’ and íaru ‘squirrel’ have become fáinne, fuar and feòrag respectively, as if an áinne uar ‘the cold ring’ was really an fháinne fhuar. Many of the words have undergone the same kinds of changes in Irish and Manx, though not all languages agree on which (e.g. Irish also has fáinne and fuar but iora respectively).
And, as in English, words that begin with n- can find this consonant being rebracketed as part of the article an. However, once this n- has been rebracketed, this now vowel-initial word can undergo the same kinds of mutation-based reshaping as an originally vowel initial word. Perhaps the most extreme example of this is ‘nettle’, which was nenaid in Old Irish, but in Scottish Gaelic can be (depending on who you ask) any of neanntag, eanntag (with the n- rebracketed away), feanntag (with the f- appended by lenition reversal) and deanntag (where the d- is apparently a hypercorrective reversal of a process of nasalisation in the Northwestern dialects)!
neanntag, eanntag, feanntag or deanntag?
So, when searching around for a word in a dictionary or an old text, be cautious; simply looking for the first consonant to give you a clue might be misleading when taken out of context. Furthermore, instances like these make clear that language is primarily a spoken phenomenon and the kinds of changes that we see reflect that: while in a written text the different between a newt and an ewt is obvious, in spoken language the question of where one word ends and the nexts begins is not so straightforward as a casual glance at a dictionary might suggest. Perhaps this should then make us ponder further how much written language is a direct reflection of spoken language versus being at least partially arbitrary choices made by the writers.
You may be familiar with the fact that the Germans refer to themselves as Deutsch and their country as Deutschland, and we find this term also in most other Germanic languages, such as Dutch Duits or Swedish Tysk, as well as Italian Tedesco. However, there are many other names in other parts of Europe. The French and Spaniards call them Allemand/Alemán, as do the Welsh with Almaenaidd; the various Slavic languages share a different term again, seen in e.g. Polish Niemiec or Russian Nemets. In the Baltic the Lithuanians and Latvians have their own terms not seen anywhere else (Vokietis and Vācijis respectively), while in Finland and Estonia they call them Saksi. We could also add some assorted forms from smaller languages, such as Miksas from Old Prussian, an extinct sister language to Lithuanian and Latvian.
The Deutsches Eck, or ‘German corner’, in Koblenz
Now, it is not unusual for inhabitants of a country to refer to themselves and their country with a different form from that used by outsiders (when was the last time you called China Zhongguo or India Bharat?). What is particularly notable about the German case, however, is the diversity even among its immediate neighbours. Contrast e.g. France, where everyone uses some form of derivative of Latin Francia (after the Germanic tribe the Franks), though the Greeks still call it Gallia after the Roman province of Gaul. Similarly, most call Spain some form derived from Hispania and Italy one from Italia. So, this diversity in names for the Germans requires some explanation.
Whence this plethora of terms? A consideration of history leads us to our answer. Recall that the modern country of Germany is a relatively recent creation, only being officially united in the mid 19th century by Otto von Bismarck. While there was a political entity that occupied the area in the form of the Holy Roman Empire it was only a relatively loose collection of small states, and prior to that the area was inhabited by a number of distinct Germanic-speaking peoples.
As a result, some of these names derive from the individual groups or tribes which lived in part of the area: so in the Western Romance and Brittonic Celtic languages the name of the Alemanni tribe was applied to the Germans as a whole. The same process occurred in the northeast with the Baltic Finns and the Saxons: not only were the Saxons the nearest group, but also, due to a combination of the Hanseatic League controlling trade through the Baltic and the anti-pagan crusading of the Teutonic Knights (another Deutsch-relative, see below), many Saxons came to settle in the Eastern Baltic, with some of their descendants still living in Estonia and Latvia today. Some small varieties show different groups again: some of the smaller Germanic varieties use a form derived from Prussian, after the state which ended up uniting the German peoples.
English takes a slightly different approach, deriving the term Germans from the Latin name of the region; Germania. This term included two Roman provinces covering much of modern-day Belgium, Switzerland, parts of eastern France and the Rhineland in modern Germany, as well as applying to the larger swathe of barbarian territories further east. Interestingly, several languages use this term to refer to Germany the country despite using a different term to refer to the Germans: Italian and Russian are the most notable examples.
We find a different source again with the Slavic Nemets terms. There is again some dispute in origin, but the general consensus is that it derives from a Slavic root *němъ meaning ‘mute’, itself of contested origin. The meaning likely was not ‘mute’ necessarily, but rather simply denoted that these groups were not Slavic-speaking. This puts in a similar group to the word ‘barbarian’ in fact, which derives from a Greek word meaning ‘those who go bar-bar/talk incomprehensibly’. Similar origins to do with ‘talking’ are likely behind the Baltic Vok-/Vāc-/Miks- forms as well.
Finally, what of German ‘Deutsch’? Well, as is the case with many endonyms it is a relatively simple and self-referential etymology. It ultimately derives from an Indo-European root *tewteh2 meaning simply ‘people’, which shows up also in e.g. Irish túath with the same meaning. This form may also be the source of Romance forms such as Spanish todo or French tout meaning ‘everyone/everything’. This root even survives in Slavic, in Russian giving the form čužoj, meaning ‘foreign, alien’. This ended up as Germanic *þeudō, which through an adjective formation *þiudiskaz meaning something like ‘of the people’ ultimately leads to the modern German form. This form also gives Latin Teutones, a likely Celtic or Germanic tribe which lived in the North German region and was encountered by the Romans early in their expansion northwards.
So, as with many other terms, such as the aubergine words which have been discussed here before, the differences between languages are reflective of a complex history. In this case the wide array of disparate terms of different etymologies reflects the complex history of the entity involved, specifically the absence of a country that even called itself ‘Germany’ until the modern era, as well as the extent to which different groups of ethnic Germans have moved about in Europe.
Have you ever encountered the form twote as a past tense of the verb to tweet? It is something of a meme on Twitter, and a live example of analogy (and its mysteries). However surprising the form may sound if you have never encountered it, it has been the prescribed one for a long time:
It is clear that this unusual form replacing tweeted is some sort of form, but why specifically twote? I saw here and there a reference to the verb to yeet, a slang verb very popular on the internet and meaning more or less “to throw”. Rather than a regular form yeeted, the past for to yeet is often taken to be yote. The choice of an irregular form is probably meant to produce a comedic effect.
This, precisely, is analogical production: creating a new form (twote) by extending a contrast seen in other words (yeet/yote). Analogy is a central topic in my research. I have been trying to answer questions such as: How do we decide what form to use ? How difficult is it to guess? How does this contribute to language change?
But first, have you answered the poll?
Here at the SMG we need to know: What do you think the past tense of 'I tweet' is?
To investigate further why we would say twote rather than tweeted, I took out my PhD software (Qumin). Based on 6064 examples of English verbs1, I asked Qumin to produce and rank possible past forms of tweet2. To do so, it read through examples to construct analogical rules (I call them patterns), then evaluated the probability of each rule among the words which sound like tweet.
Qumin found four options3: tweeted (/twiːtɪd/), by analogy with 32 similar words, such as greet/greeted; twet (/twɛt/), by analogy with words like meet/met; tweet (/twiːt/) by analogy with words like beat/beat, finally twote (/twəˑʊt/), by analogy with yeet. Figure 1 provides their ranking (in ascending order) according to Qumin, with the associated probabilities.
Figure 1. Qumin’s ranking of the probability for potential past forms of to tweet
As we can see, Qumin finds twote to be the least likely solution. This is a reasonable position overall (indeed, tweeted is the regular form), so why would both the official Twitter account and many Twitter users (including several linguists) prefer twote to tweeted?
But Qumin has no idea what is cool, a factor which makes yeet/yote (already a slang word, used on the internet) a particularly appealing choice. Moreover, Qumin has no access to semantic similarity, which could also play a role. Verbs that have similar meanings can be preferred as support for the analogy. In the current case, both speak/spoke and write/wrote have similar pasts to twote, which might help make it sound acceptable. Some speakers seem to be aware of these factors, as seen in the tweet above.
Is it twankt or twunkt? I'm thinking about the past-tense of tweet.
Are most speakers aware of the variant twote and using it? Before concluding that the model is mistaken, we need to observe what speakers actually use. Indeed, only usage truly determines “what is the past of tweet”. For this, I turn to (automatically) sifting through Twitter data.
A few problems: first, the form “tweet” is also a noun, and identical to the present tense of the verb. Second, “twet” is attested (sometimes as “twett”), but mostly as a synonym for the noun “tweet” (often in a playful “lolcat” style), or as a present verbal form, with a few exceptions, usually of a meta nature (see tweets below). I couldn’t find a way to automatically distinguish these from past forms while also managing within the Twitter API limits. Thus, I left out both from the search entirely. This leaves only our two main contestants.
If it's not already been formally done, I should now like to declare the past tense of "tweet" to be "twet"
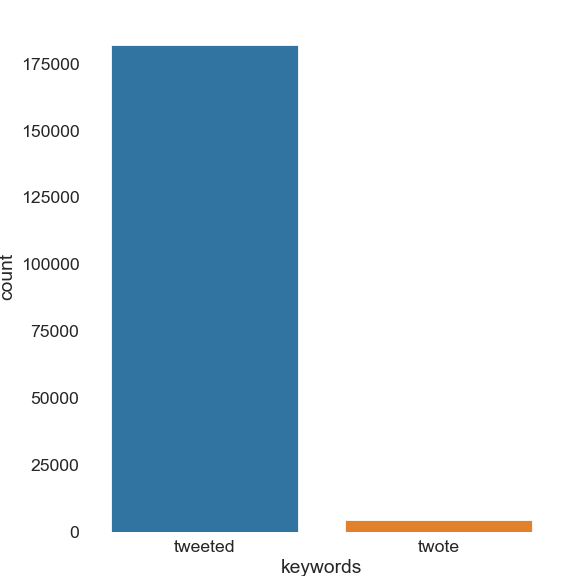
I extracted as many recent tweets containing tweeted or twote as Twitter would let me — around 300 000 tweets twotten between the 26th of August and the 3rd of September. 186777 tweets remained after refining the search4. Of these, less than 5000 contain twote:
Counts of tweets containing either of two possible pasts for the verb “to tweet” in the past few days on twitter (mentions excluded).
As you can see, the tweeted bar completely dwarfs the other one. However amusing and fitting twote may be, and despite @Twitter’s prescription (but conforming with Qumin’s prediction), the regular past form is by far the most used, even on the platform itself, which lends itself to playful and impactful statements. This easily closes this particular English Past Tense Debate. If only it were always this simple!
The English verb data I used includes only the present and past tenses, and is derived from the CELEX 2 dataset, as used in my PhD dissertation and manually supplemented by the forms for “yeet”. The CELEX2 dataset is commercial, and I can not distribute it. [↩]
The code I used for this blog post is available here, but not the dataset itself. Note that for scientific reasons I won’t discuss here, this software works on sounds, not orthography. [↩]
One last possibility has been ignored by this polite software, a form which follows the pattern of sit/sat. I see it used from time to time for its comic effect, but it does not seem at all frequent enough to be a real contestant (and I do not recommend searching this keyword on Twitter). [↩]
Since there has been a lot of discussion on the correct form, I exclude all clear cases of mentions. I count as mentions any occurrences wrapped in quotations, co-occurring with alternate forms, mentioning past tense, or with a hashtag. Moreover, with the forms in –ed, it is likely that the past participle would be identical, but for twote, the past participle could well be twotten. To reduce the bias due to the presence of more past participles in the usage of tweeted, I also exclude all contexts where the word is preceded by the auxiliary forms has, have, had, is, are, was, were, possibly separated by an adverb. [↩]
As the University of Surrey’s foremost (and indeed only) blog about languages and how they change, MORPH is enjoyed by literally dozens of avid readers from all over the world. But so far these multitudes have not received an answer to the one big linguistic question besetting modern society. Namely, what on earth is going on with the name of the plant that British English calls the aubergine, but that in other times and places has been called eggplant, melongene, brown-jolly, mad-apple, and so much more? Where do all these weird names come from?
I think the time has finally come to put everyone’s mind at rest. Aubergines may not seem particularly eggy, melonish, jolly or mad, but lots of the apparently diverse and whimsical terms for them used in English and other languages are actually connected – and in trying to understand how, we can get some insight about how vocabulary spreads and develops over time. It turns out that one powerful impulse behind language change is the fact that speakers like to ‘make sense’ of things that do not inherently make sense. What do I mean by that? Stay tuned to find out.
To get one not-so-linguistic point out of the way first, there is no real mystery about eggplant (the word generally used in the US and some other English-speaking countries, dating back to the 18th century), which is not linked to anything else I am talking about here. It is hard to imagine mistaking the large, purple fruit in the photo above for any kind of egg, but that is not the only kind of aubergine in existence. There are cultivars with a much more oval shape, and even ones with white rather than purple skin: pictures like this, showing an imposter alongside some real eggs, make it obvious how the word eggplant was able to catch on.
Meanwhile, aubergine, which is borrowed from French as you might expect, has a much more complex history, and can be traced back over many centuries, hopping from language to language with minor adjustments along the way. The plant is not native to the US, Britain or France, but to southern or eastern Asia, and investigating the history of the word will eventually take us back in the right geographical direction. Aubergine got into French from the Catalan albergínia, whose first syllable gives us a clue as to where we should look next: as in many al- words in the Iberian peninsula (e.g. Spanish algodón ‘cotton’), it reflects the Arabic definite article. So, along with medieval Spanish alberengena, the Catalan item is from Arabic al-bādhinjān ‘the aubergine’, where only the bādhinjān bit will be relevant from here on. This connection makes sense, because the Arab conquest had such an impact on the history of Iberia. And more generally, we have the Arabs to thank for the spread of aubergine cultivation into the West, and also – indirectly – for this charming illustration in a 14th-century Latin translation of an Arabic health manual:
Page from the 14th c. Tacuinum Sanitatis (Vienna), SN2644
But bādhinjān is not Arabic in origin either: it was borrowed into Arabic from its neighbour, Persian. In turn, Persian bādenjān is a borrowing from Sanskrit vātiṅgaṇa… and Sanskrit itself got this from some other language of India, probably belonging to the unrelated Dravidian family. The word for aubergine in Tamil, vaṟutuṇai, is an example of how the word developed inside Dravidian itself.
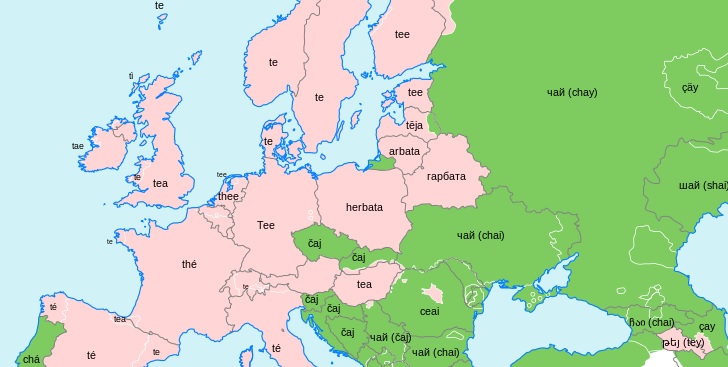
That is as far back as we are able to trace the word. But the journey has already been quite convoluted. To recap, a Dravidian item was borrowed into Sanskrit, from there into Persian, from there into Arabic, from there into Catalan, from there into French, and from there into English – and in the course of that process, it managed to go from something along the lines of vaṟutuṇai to the very different aubergine, although the individual changes were not drastic at any stage. The whole thing illustrates how developments in language can go with cultural change, in that words sometimes spread together with the things they refer to. In the same way, tea reached Europe via two routes originating in different Chinese dialect zones, and that is what gave rise to the split between ‘tea’-type and ‘chai’-type words in European languages:
[Map created by Wikimedia user Poulpy, licensed CC BY-SA 3.0, cropped for use here]This still leaves a lot of aubergine words unaccounted for. But now that we have played the tape backwards all the way from aubergine back to something-like-vaṟutuṇai, we can run it forwards again, and see what different historical paths we could follow instead. For example, Arabic had an influence all over the Mediterranean, and so it is no surprise to see that about a thousand years ago, versions of bādhinjān start appearing in Greece as well as Iberia. Greek words could not begin with b- at the time, so what we see instead are things like matizanion and melintzana, and melitzana is the Greek for aubergine to this day. There is no good pronunciation-based reason for the Greek word to have ended up beginning with mel-, but what must have happened is that faced with this foreign string of sounds, speakers thought it would be sensible for it to sound more like melanos ‘dark, black’, to match its appearance. That is, they injected a bit of meaning into what was originally just an arbitrary label.
Meanwhile the word turns up in medieval Latin as melongena (giving the antiquated English melongene) and in Italian as melanzana, and a similar thing happened: here mel- has nothing to do with the dark colour of the fruit, but it did remind speakers of the word for ‘apple’, mela. We know this because melanzana was subsequently reinterpreted as the expression mela insana, ‘insane apple’. To produce this interpretation, it must have helped that the aubergine (like the equally suspicious tomato) belongs to the ‘deadly’ nightshade family, whose traditional European representatives are famously toxic. So, again, something that was originally just a word, with no deeper meaning inside, was reimagined so that it ‘made sense’. As a direct translation, English started calling the aubergine a mad-apple in the 1500s.
Poster from a 16th c. aubergine factory
There are many more developments we could trace. For example, I have not talked at all about the branch of this aubergine ‘tree’ that entered the Ottoman Empire and from there spread widely across Europe and Asia. But instead I will return now to the Arab conquest of Iberia. This brought bādhinjān into Portuguese in the form beringela, and then when the Portuguese started making conquests of their own, versions of beringela appeared around the world. Notably, briñjal was borrowed into Gujarati and brinjal into Indian English, meaning that something-like-vaṟutuṇai ultimately came full circle, returning in this heavy disguise to its ancestral home of India. And to end on a particularly happy note, when the same form brinjal reached the Caribbean, English speakers there saw their own opportunity to ‘make sense’ of it – this time by adapting it into brown-jolly.
Brown-jolly is pretty close to the mark in terms of colour, and it is much better marketing than mela insana. But from the linguist’s point of view, they both reinforce a point which has often been made: speakers are always alive to the possibility that the expressions they use are not just arbitrary, but can be analysed, even if that means coming up with new meanings which were not originally there. To illustrate the power of ‘folk etymology’ of this kind, linguists traditionally turn to the word asparagus, reinterpreted in some varieties of English as sparrow-grass. But perhaps it is time for us to give the brown-jolly its moment in the sun.
How do we talk about time? This may seem a simple question with a simple answer; we are all human, surely we all experience time the same way? That may be true, but that doesn’t mean that all languages organise the time in the same way. This is arguably most apparent when it comes to talking about the days either side of the present day. We all live on earth and so therefore all experience a day-night cycle; all can understand how one day follows after another. However, the words we use to locate events in this cycle can vary wildly in their construction.
Let’s take a look at two languages, Scottish Gaelic and Sylheti, and see how their systems compare with that of English. All three of these languages belong to the same family, Indo-European, so it might be assumed that they show many similarities. And yet each still exhibits significant variation in how they talk about time.
Firstly, Scottish Gaelic. Like English, it distinguishes between ‘yesterday’, ‘today’ and ‘tomorrow’. The terms each show a consistent structure with a frozen prefix a(n)- with three morphologically opaque roots; an-dè, an-diugh and a-màireach respectively. Furthermore none of the Gaelic terms has any connection with the normal word for ‘day’, latha/là. Compare English, where yester-day and to-day both feature the word ‘day’, while to-day and to-morrow both feature a frozen prefix to- (historically a demonstrative). Additionally, there are also single terms for ‘last night’ as well as ‘tonight’ with a-raoir and a-nochd respectively, again with no immediately apparent connection with the normal term for ‘night’ oidhche. On the other hand, there is no single term for ‘tomorrow night’ so the compound expression oidhche a-màireach is used instead. There are also additional terms for ‘the day after tomorrow’ and ‘the day before yesterday’, an-earar and a bhòn-dè respectively, while the latter has a counterpart in a bhòn-raoir for ‘the night before last’. English is also reported to have had similar terms in the form of ereyesterday and overmorrow, though these have fallen out of usage in the modern day.
Gaelic is also in another respect slightly more regular than English in how it refers to parts of the day. While in English we have a split between ‘this morning’ and ‘yesterday morning’, Gaelic instead uses madainn an-diugh and madainn an-dè, where the former literally translates to ‘today morning’.
But all this is not really that surprising. All that really distinguishes Scottish Gaelic from English in this respect is which time categories are given single indivisible terms rather than compositional expressions; the fundamental organisation of the system is still broadly similar to English. To see a far more radically different system of organising time words, we will now turn to Sylheti, an Indo-Aryan language spoken in north-eastern Bangladesh by around 9-10 million and by perhaps a further 1 million in diaspora, including by most of the British Bangladeshi community.
Here, instead of distinguishing between ‘yesterday’ and ‘tomorrow’, we instead find a single term xail(ku), contrasting with aiz(ku) meaning ‘today’ (the -ku is a suffix which can optionally appear on a lot of ‘time’ words, such as onku ‘now’ or bianku ‘(this) morning’). The two senses of ‘tomorrow’ and ‘yesterday’ can be distinguished by combining them with goto ‘past’ and agami ‘future’, but just as commonly instead the distinction is solely marked by whether the verb is in the past or future tense, e.g. xailku ami amar bondu dexsi ‘I saw my friend yesterday’ vs. xailku ami amar bondu dexmu ‘I will see my friend tomorrow’.
This is not an isolated instance in the language, either, but in fact represents a consistent trend. So in the same manner foru can be either ‘the day before yesterday’ or ‘the day after tomorrow’ depending on context and toʃu the same but at one day further removed.
Visualising the systems
Nor is Sylheti unique in using this kind of system; it is also found in many parts of New Guinea, for example. Yimas, a language of northern New Guinea, also uses the same term ŋarŋ for both ‘yesterday’ and ‘tomorrow’, urakrŋ for ‘two days removed’ and so on, all the way up to manmaɲcŋ for ‘five days removed’. Once again whether the reference is to the past or future is carried by the choice of tense on the verb, though Yimas has a far more complex system than that seen in Sylheti, for instance distinguishing a near past -na(n) from a more remote past -ntuk~ntut.
Sylheti also has more fine grained distinctions for parts of the day than either English or Scottish Gaelic. For example, if one wishes to say ‘in the morning’ one must decide whether one is talking about the early morning (ʃoxal) or the mid to late morning (bian). Additionally, while forms such as ‘yesterday/tomorrow afternoon’, ‘the night before last/after next’ and ‘yesteray/tomorrow morning’ use compound expressions (xail madan, foru rait and xail bian/ʃoxal respextively), to express ‘this morning/this afternoon/tonight’ the word for the part of the day (perhaps with the oblique suffix -e or a time suffix -ku) is sufficient by itself, for example amra ʃoxale Sylheʈ aisi ‘We arrived in Sylhet this morning’ or ami raitku dua xotram ‘I am praying tonight’ (with rait ‘night’).
This is just one small part of the temporal vocabulary, and only looking at representatives from a single family, and yet already we see great variation in how time is organised and discussed. It is not so much that these groups have fundamentally different conceptions of time, as these languages share a common ancestor and are only separated by a few thousand years. Instead, it is a testament to the fluidity of time itself, resulting in the words used to refer to it easily shifting in meaning and being reorganised over generations.
What slips of the tongue can tell us about language
“The grouchy knight cuddled the rowdy seer’s adorable puppy while devouring lasagne”
This is probably a sentence you’ve never heard – or produced – before. Yet this experience is not novel – everyday, you make utterances you’ve never heard, and understand new ones.
Producing such utterances is not a trivial matter. To do this we have to generate them – that is, decide on the concept to be expressed, encode that into words and structures, then into the sounds that make up our words before sending instructions to our articulatory apparatus to produce the utterance. All within fractions of a second.
Yet, sometimes we make mistakes, and produce things we didn’t intend to do:
Error (The Mistake we Make)
Target (What we had intended to say)
heft lemisphere
left hemisphere
squoor
squeaky floor
a leading list
a reading list
gave the goy
gave the boy
stough competition
stiff/tough competition
she sliced the knife with a salami
she sliced the salami with a knife
a hole full of floors
a floor full of holes
We usually notice these errors when we make them and correct ourselves. But rather than being merely slips of tongue, they are a goldmine of information as they demonstrate breakdowns at various parts in the speech production process.
Some of these errors are lexical selection errors – we select the wrong lexical concept or lemma for the message we’re trying to say. That is, we select the wrong word stored in our brains, we pick the wrong word from our mental dictionary. This can be simply the wrong concept, as in: ‘he’s carrying a bag of cherries’ instead of ‘grapes’. Sometimes, we can combine words together in blends: ‘the competition is getting a little stough’ instead of stiff or tough. Other times, we can exchange words within a sentence, as in ‘she sliced the knife with a salami’, rather than ‘she sliced the salami with a knife’.
We can also make phonological errors, that is, errors in the sound structure of our words:
Exchanges
heft lemisphere
left hemisphere
fleaky squoor
squeaky floor
cheek and ch[ɔː]se
Chalk and cheese
Additions
enjoyding it
enjoying it
Deletions
cumsily
Clumsily
Anticipations
leading list
reading list
Perseverations
gave the goy
gave the boy
We can look at large data sets, or corpora, to see what kinds of errors are commonly made. We find that these errors are still well-formed in terms of their sound structure, or phonology. 60-90% of errors (depending on the corpus you look at) involve errors with a single sound or segment, and these errors are sensitive to syllable structure. That is, we might swap segments from the same part of the syllable as in exchanges:
face spood <space food
Or we might combine the beginning of one syllable and the end of another:
grool < great + cool
We also like to swap sounds that are similar to each other, so
paid mossible < made possible
is more likely than
two sen pet < two pen set
There are exceptions to these generalisations of course – but they are rare.
Speech errors give us an insight into normal speech production processes. The fact that sound errors occur at all tells us that speech production is a generative process – it is not that we just reproduce fully formed stored sentences, but rather we create each utterance afresh each time. In order to mix or swap two elements, both must be activated at the same point of the production process.
Furthermore, the range of speech across which errors can occur implies that the span of processing is greater than a single word. You might be familiar with spoonerisms, popularised by Dr William Archibald Spooner:
You were caught fighting a liar in the quad < You were caught lighting a fire in the quad
You have hissed my mystery lectures < You have missed my history lectures
You have tasted the whole worm < You have wasted the whole term
We must plan more than a word ahead for errors like these to happen.
There is a much wider array of questions we can ask about speech production than can be answered by speech errors, but certainly they are an entertaining place to start.
There’s been excitement recently about evidence that humans had set foot in the Americas as much as 22,500 years ago, pushing back the previous best estimate by almost ten thousand years. And by ‘set foot’, I mean literally. The tell-tale new evidence comes to us in the form of imprints left by human feet in a particularly well-preserved mudflat in New Mexico. So far, the humans themselves have not been uncovered by archaeologists, but their characteristic mark upon the mud has endured.
When linguists peer into the past, we also will occasionally use the imprints, left by something which has otherwise been lost, to infer its presence long ago — all of which brings us to the topic of feet, and not the kind that you’d use to walk across a mudflat, but the literal English word ‘feet’, which itself contains a wonderful imprint of a long-lost vowel.
Our story begins with the fact that in English, the word ‘feet’ is a little odd. It’s a plural that doesn’t end in ‘s’. As any child will tell you, you can’t get away with saying ‘foots’ for the plural of ‘foot’ for very long before someone bigger than you corrects it to ‘feet’. However, given that most English nouns do use an ‘s’ plural, it’s entirely sensible to ask why ‘feet’ is different. (Of course, ‘feet’ isn’t absolutely unique: English contains a select club of other, similar plurals like ‘geese’ and ‘teeth’, to which we’ll return in a minute.)
The tale of ‘feet’ begins around two millennia ago, when it was in fact a regular plural word. In proto-Germanic, the singular form would have been ‘fōt-s’ (pronounced approximately as fohts, where ‘ō’ is a long ‘o’ sound) and its corresponding plural ‘fōt-iz’, constructed with a simple plural suffix ‘-iz’. Over the following centuries, the sounds at the end of the plural form were worn away and eventually lost, as often happens during language change. However, before the suffix disappeared entirely, the ‘i’ vowel in it left its imprint on the ‘ō’ vowel, changing it to ‘ȫ’, which is to say ‘fōtiz’ became ‘fōti’ then ‘fȫti’ then ‘fȫt’ which by Old English had become ‘fēt’ and is now ‘feet’. In the meantime, the singular form ‘fōts’, which contained no ‘i’ vowel, changed very little indeed: it lost its suffix ‘-s’, becoming ‘fōt’ and then modern English ‘foot’. A similar story lies behind the plurals ‘geese’ and ‘teeth’: an original suffixal vowel ‘i’ changed ‘ō’ into ‘ȫ’, before disappearing, then ‘ȫ’ became ‘ē’.
You might say that the ‘i’ vowel left its imprint upon original ‘ō’ in the form of the altered vowel ‘ȫ’. One tool which linguistic archaeologists put to good use, is our knowledge of the characteristic imprints that one sound can leave upon another. In the case of the long-lost ‘i’ vowel, the imprint even has a name, umlaut. Historical umlaut is also what lies behind plurals like ‘mice’ and ‘men’.
Armed with the background knowledge that lost ‘i’ vowels changed ‘ō’ into ‘ȫ’, and in doing so gave rise to modern English alternations between ‘oo’ and ‘ee’, we can now go fossicking through the vocabulary for more lost ‘i’ vowels. Another suffix that was lost over the centuries was a causative suffix, which related nouns to verbs, such as ‘blood’ to ‘bleed’, or ‘food’ to ‘feed’: as you’ll have guessed, the verbs once contained a now-lost ‘i’. In some cases, pairs of sibling words such as these have grown apart over time. For instance, if you were to decide someone’s fate (or their ‘doom’) then you’d be judging them (or ‘deeming’ them), though as you can see, I had to produce a fairly contrived context to highlight the relatedness of ‘doom’ and ‘deem’.
Umlaut caused by a now-lost ‘i’ also crops up in several nouns ending in ‘-th’: compare not only ‘strong’ with ‘strength’, ‘long’ with ‘length’, or ‘broad’ with ‘breadth’, but also ‘hale’ with ‘health’ and ‘foul’ with ‘filth’.
feet made filthy by umlaut!
Over decades of meticulous work, linguists have uncovered much about how languages around the world change over time, though much more still remains to be accounted for. One of the many lingering questions is what the conditions are, which favour the continued survival of idiosyncratic word forms like ‘feet’, long after they have lost their regularity. We know that many irregular words, such as the Old English plural ‘bēc’ for ‘books’ (corresponding to singular ‘bōc’), get removed over time, yet others persist for millennia. It’s an ongoing task for linguists to understand why some footprints remain while others get washed away.
SMG – I’d Arapaho, Roon, Sala, Tubar and Nara, but alas no Oroha paradigms
A palindrome is a linguistic delight: it reads the same in both directions. For example: level. Or Anna, or indeed Hannah. This is a visual trick: if you record yourself saying one of these words and play the recording backwards, it won’t sound exactly the same.
Palindromes hit the big time in the parrot sketch. They were also promoted by ABBA, with their top hit SOS!
Here’s a nice one from North Ambrym (an Oceanic language spoken in Vanuatu): rrirrirr ‘sound a rat makes when you try and kill it but you miss it’. And a long one from Estonian: kuulilennuteetunneliluuk ‘bullet flying trajectory tunnel’s hatch’. I’m not sure that one is used much (except in blogs about palindromes).
We can go up a level (!), as it were, to palindromic phrases. A famous one of these is:
A man, a plan, a canal – Panama!
This has been around at least since 1948. It has often been extended, as in this version due to Guy Jacobson:
A man, a plan, a cat, a ham, a yak, a yam, a hat, a canal – Panama!
And here’s a Russian sentence palindrome: Рислинг сгнил, сир. ‘the Riesling has gone off, sir’ More Russian palindromes at https://bit.ly/3AtxBID. For French sentence palindromes go to https://bit.ly/3kmC5LE. And there are even songs based on such palindromes:
They have palindromes in American Sign Language:
Not surprisingly, palindromes don’t translate. Though we can go up another level (!) of cleverness, to the bilingual palindrome: I love / e voli. This is half English, half Italian, and overall a palindrome. More of these at https://bit.ly/39ohoZy. It’s truly amazing what people can create, including whole poems as palindromes: https://bit.ly/3tTWtaa.
Some time ago, I mentioned to linguist colleagues that Malayalam (a Dravidian language of southern India) is a palindromic language. One colleague’s eyes opened wide, and he asked whether it was palindromic at the word level or the sentence level. What a great idea! Of course, it’s just the name which is a palindrome (just as Anna is a palindrome but that doesn’t make Anna a palindromic person – there are deep issues here: what does a name refer to?).
It turns out that there are over seventy “palindromic languages”, including some that are central to our research in SMG, notably Iaai (spoken in New Caledonia). Here are some more: Efe, Ewe, and Atta.
What then of E (also called Wuse/Wusehua), a Tai-Chinese mixed language, of Guangxi, China? Yes, it’s a palindrome, just not a very impressive one. Just as the English pronoun I is a palindrome, though hardly one to get excited about (unless you’re called Anna or Hannah of course). But it gets much better. You may have noticed that linguists increasingly give three letter codes after language names. These are the ISO codes that we use to uniquely identify a language, to make sure that we’re talking about, say, the language Aja (a Nilo-Saharan language of Sudan), ISO code aja, and not Aja (a Niger-Congo language of Benin), ISO code ijg. So, what is the ISO code for the language E? It’s eee. The language name and the code are both palindromes! Similarly there’s U (an Austroasiatic language of the Yunnan Province of China), ISO code uuu.
Here are the languages which are doubly palindromic (name and ISO code):
Name
ISO code
E
eee
Efe
efe
Ewe
ewe
Iaai
iai
Kerek
krk
Naman
lzl
Mam
mam
Nen
nqn
Ofo
ofo
Ososo
oso
Utu
utu
U
uuu
Yoy
yoy
A real star is Naman, whose ISO code is quite different, lzl, but still palindromic. Where does that come from? Well, the language has an alternative name, Litzlitz, so when it’s not a palindrome it’s a reduplication!
Back to the tricky use of “palindromic language”. Iaai is a palindromic name. As we’ve seen, its ISO code iai is also a palindrome. And the language does have some very nice palindromes:
aba ‘caress’
ee ‘locative – near the interlocuter’
ii ‘to suck’
iei ‘to hurt, cause pain’
ikiiki ‘repugnant’
iwi ‘rudder’
komok ‘sick’
maam ‘your manner’
mem ‘Napolean fish (Cheilinus undulatus)’
omoomo ‘women’
nokon ‘his/her infant’
oṇo ‘Barracuda (Sphyraena sp.)’
öö ‘spear’
ölö ‘mount, embark, disembark’
ölö ‘legume (Pueraria sp.)’
u ‘an old word for yam’
uu ‘fall from a height, chop down (of tree)’
ûû ‘a dispute, to dispute’
ûcû ‘similar, same’ (a nice meaning for a palindrome!)
ûcû ‘to exchange, buy, shop’
It would be impressive if you could read this post backwards, and have it make sense. But that wouldn’t be a BLOG but a GLOB, the latter being is an instance of a Semordnilap, but that is another story. For now, we welcome your favourite palindromes, in any language, in the comments.
For examples, thanks to Jenny Audring, Sacha Beniamine, Marina Chumakina, Mike Franjieh, Erich Round and Anna Thornton, and for the title (you’ve guessed what sort of title that is!), thanks to Steven Kaye.
As everyone knows by now, for the foreseeable future we must all stay at home as much as possible to slow the spread of COVID-19 and reduce the burden on our health services – which has already been substantial, and will soon be enormous even in the best possible scenario.
This shift in the way we operate as a society will have a wide range of effects on our lives, which are already being noticed. Some of these were the kind of thing you might have thought of in advance – but others less so. For example, soon after the advice to work from home really started to bite in the US, a substantial thread developed on Twitter, all started off by the following tweet:
The thousands of responses that appeared within a few hours of this tweet shows how deeply it resonated: many people must have been through their own version of the same surprising experience, some of them presumably in the last few days. But what happened here, and why was it so surprising? And why, as a linguist, am I sitting at home and writing a blog post about it now?
This single tweet, which people found so easy to identify with, in fact brings together a number of issues that linguists are interested in. For one thing, it works as a clear illustration of a point that people intuitively appreciate, but which has endless ramifications: the language you use is never just an instrument for communicating your thoughts, but is also taken to say something important about your identity, whether you intend it to or not. If a guy uses the expression “let’s circle back”, meaning to return to an issue later, that makes him a “let’s circle back” guy – that is, a particular kind of person. In a jokey way, the tweeter is implying that she already had a mental category of ‘the kind of person who would say things like that’, and she takes it for granted that we do too. In this case, the surprise for Laura Norkin was in suddenly discovering that her own husband belonged in that pre-existing category: the way she tells it, hearing him use a specific turn of phrase counted as finding out important new information about who he is as a person, which she was not necessarily best pleased about.
Making a linguistic choice: a bilingual road sign in Wales
Since the mid-twentieth century, the field of sociolinguistics has drawn attention to the fact that this kind of thing is going on everywhere in language. Consciously or unconsciously, people are making linguistic choices all the time – whether that means choosing between two totally different languages, between two different expressions with the same meaning (do you circle back to something or just return to it?), or between two very slightly different pronunciations of the same word. Any of these choices might turn out to ‘say something’ about how you see yourself – or how other people see you. And the social meanings and values assigned to the different choices are likely to change over time: so understanding what is going on with one person’s use of language really requires you to understand what is going on right across the community, which is like an ecosystem full of co-existing language diversity. How do linguistic developments, and the social responses to them, propagate and interact in this ecosystem? That’s something that researchers work hard to find out.
The tweet also picks up on the importance of the situational context for the way people use language. Laura Norkin had never heard her husband use the offending expression before because it belongs to a particular register – meaning a variety of language which is characteristic of a particular sphere of activity. Circling back is characteristic of ‘full work mode’, something which had never previously needed to surface in the domestic setting.
Why do registers exist? Partly it must be to do with the fact that different people know different things: for example, lawyers can expect to be able to use technical legal terminology with their colleagues, but not with their clients, even if they are talking about all the same issues – because behind the terminology there lies a wealth of specialist knowledge. Similarly, anyone would modify their language when talking to a five-year-old as opposed to a fifty-year-old.
But this cannot be the whole story: it doesn’t help you to explain the difference between returning and circling back. Should we think of the business/marketing/management world, where terms like circling back are stereotypically used, as a mini community within the community, with its own ideas of what counts as normal linguistic practice? Or is everyone involved giving a signal that they take on a new, businesslike identity when they turn up to the office – even if these days that doesn’t involve leaving the house? Again, working out the relationship between the language aspect and the social aspect here makes an interesting challenge for linguistics.
The medical profession is well known for having its own technical register
But this was not just an anecdote about how unusual it is to be at home and yet hear terms that usually turn up at work. We can tell that “let’s circle back”, just like other commonly mocked corporate expressions such as “blue-sky thinking” or “push the envelope”, is something we are expected to dislike – but why? The existence of different registers is not generally thought of as a bad thing in itself. You could give the answer that this expression is overused, a cliché, and thus sounds ugly. But really, things must be the other way round: English abounds in commonly used expressions, and only the ones that ‘sound ugly’ get labelled as overused clichés. And there is nothing inherently worse about circle back than about re-turn – in fact, when you think about it, they are just minor variations on the same metaphor.
So what is really going on here? The popular reaction to circle back, and other things of that kind, seems to involve lots of factors at once. The expression is new enough that people still notice it; but it is not unusual enough to sound novel or imaginative. It is currently restricted to a particular kind of professional setting that most people never find themselves in; but it does not refer to a complex or specific enough concept to ‘deserve’ to exist as a technical term. And we do not tend to worry too much about making fun of the linguistic habits of people who have a relatively privileged position in society: certainly, teasing your husband by outing him as a “let’s circle back” guy is not really going to do him any harm.
Spelling it out like this helps to suggest just how much information we are factoring in whenever we react to the linguistic behaviour of the people around us – and this is something we do all the time, mostly without even noticing. We are social beings, and cannot help looking for the social message in the things people say, as well as the literal message: establishing this fact, and working out how to investigate it scientifically, has been one of the great overarching projects of modern linguistics. Right now, for everyone’s benefit, we need to learn how to be less sociable than ever. But as the tweet above suggests, people’s inbuilt sensitivity to language as a social code is not going to change any time soon.