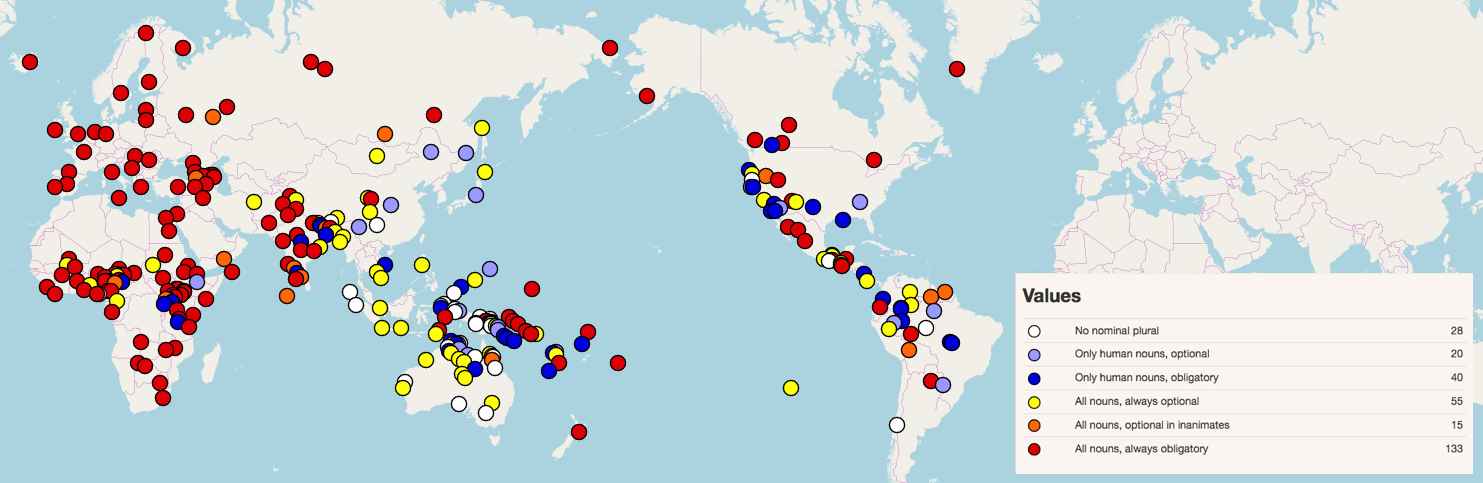
Today’s vocabulary, tomorrow’s grammar
If an alien scientist were designing a communication system from scratch, they would probably decide on a single way of conveying grammatical information like whether an event happened in the past, present or future. But this is not the case in human languages, which is a major clue that they are the product of evolution, rather than design. Consider the way tense is expressed in English. To indicate that something happened in the past, we alter the form of the verb (it is cold today, but it was cold yesterday), but to express that something will happen in the future we add the word will. The same type of variation can also be seen across languages: French changes the form of the verb to express future tense (il fera froid demain, ‘it will be cold tomorrow’, vs il fait froid aujourd’hui, ‘it is cold today’).
The future construction using will is a relatively recent development. In the earliest English, there was no grammatical means of expressing future time: present and future sentences had identical verb forms, and any ambiguity was resolved by context. This is also how many modern languages operate. In Finnish huomenna on kylmää ‘it will be cold tomorrow’, the only clue that the sentence refers to a future state of affairs is the word huomenna ‘tomorrow’.

How, then, do languages acquire new grammatical categories like tense? Occasionally they get them from another language. Tok Pisin, a creole language spoken in Papua New Guinea, uses the word bin (from English been) to express past tense, and bai (from English by and by) to express future. More often, though, grammatical words evolve gradually out of native material. The Old English predecessor of will was the verb wyllan, ‘wish, want’, which could be followed by a noun as direct object (in sentences like I want money) as well as another verb (I want to sleep). While the original sense of the verb can still be seen in its German cousin (Ich will schwimmen means ‘I want to swim’, not ‘I will swim’), English will has lost it in all but a few set expressions like say what you will. From there it developed a somewhat altered sense of expressing that the subject intends to perform the action of the verb, or at least, that they do not object to doing so (giving us the modern sense of the adjective ‘willing’). And from there, it became a mere marker of future time: you can now say “I don’t want to do it, but I will anyway” without any contradiction.
This drift from lexical to grammatical meaning is known as grammaticalisation. As the meaning of a word gets reduced in this way, its form often gets reduced too. Words undergoing grammaticalisation tend to gradually get shorter and fuse with adjacent words, just as I will can be reduced to I‘ll. A close parallel exists in in the Greek verb thélō, which still survives in its original sense ‘want’, but has also developed into a reduced form, tha, which precedes the verb as a marker of future tense. Another future construction in English, going to, can be reduced to gonna only when it’s used as a future marker (you can say I’m gonna go to France, but not *I’m gonna France). This phonetic reduction and fusion can eventually lead to the kind of grammatical marking within words that we saw with French fera, which has arisen through the gradual fusion of earlier ferre habet ‘it has to bear’.
Words meaning ‘want’ or ‘wish’ are a common source of future tense markers cross-linguistically. This is no coincidence: if someone wants to perform an action, you can often be reasonably confident that the action will actually take place. For speakers of a language lacking an established convention for expressing future tense, using a word for ‘want’ is a clever way of exploiting this inference. Over the course of many repetitions, the construction eventually gets reinterpreted as a grammatical marker by children learning the language. For similar reasons, another common source of future tense markers is words expressing obligation on the part of the subject. We can see this in Basque, where behar ‘need’ has developed an additional use as a marker of the immediate future:
ikusi behar dut
see need aux
‘I need to see’/ ‘I am about to see’
This is also the origin of the English future with shall. This started life as Old English sceal, ‘owe (e.g. money)’. From there it developed a more general sense of obligation, best translated by should (itself originally the past tense of shall) or must, as in thou shalt not kill. Eventually, like will, it came to be used as a neutral way of indicating future time.
But how do we know whether to use will or shall, if both indicate future tense? According to a curious rule of prescriptive grammar, you should use shall in the first person (with ‘I’ or ‘we’), and will otherwise, unless you are being particularly emphatic, in which case the rule is reversed (which is why the fairy godmother tells Cindarella ‘you shall go to the ball!’). The dangers of deviating from this rule are illustrated by an old story in which a Frenchman, ignorant of the distinction between will and shall, proclaimed “I will drown; nobody shall save me!”. His English companions, misunderstanding his cry as a declaration of suicidal intent, offered no aid.
This rule was originally codified by Bishop John Wallis in 1653, and repeated with increasing consensus by grammarians throughout the 18th and early 19th centuries. However, it doesn’t appear to reflect the way the words were actually used at any point in time. For a long time shall and will competed on fairly equal terms – shall substantially outnumbers will in Shakespeare, for example – but now shall has given way almost entirely to will, especially in American English, with the exception of deliberative questions like shall we dance? You can see below how will has gradually displaced shall over the last few centuries, mitigated only slightly by the effect of the prescriptive rule, which is perhaps responsible for the slight resurgence of shall in the 1st person from approximately 1830-1920:
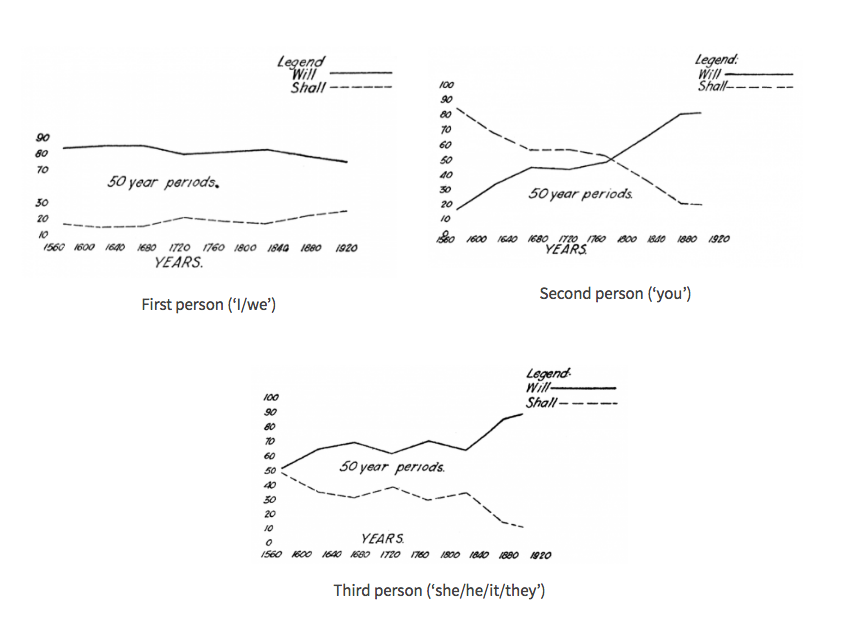
Until the eventual victory of will in the late 18th century, these charts (from this study) actually show the reverse of what Wallis’s rule would predict: will is preferred in the 1st person and shall in the 2nd , while the two are more or less equally popular in the 3rd person. Perhaps this can be explained by the different origins of the two futures. At the time when will still retained an echo of its earlier meaning ‘want’, we might expect it to be more frequent with ‘I’, because the speaker is in the best position to know what he or she wants to do. Likewise, when shall still carried a shade of its original meaning ‘ought’, we might expect it to be most frequent with ‘you’, because a word expressing obligation is particularly useful for trying to influence the action of the person you are speaking to. Wallis’ rule may have been an attempt to be extra-polite: someone who is constantly giving orders and asserting their own will comes across as a bit strident at best. Hence the advice to use shall (which never had any connotations of ‘want’) in the first person, and will (without any implication of ‘ought’) in the second, to avoid any risk of being mistaken for such a character, unless you actually want to imply volition or obligation.
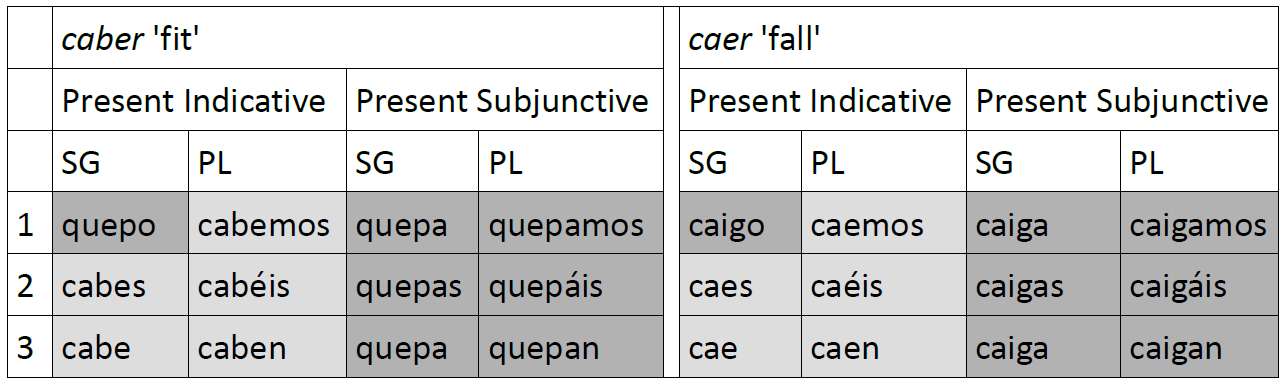
 Considering that the majority of English speakers learn the language in adulthood, when our brains have lost much of their early plasticity, it’s just as well that some aspects of English grammar are pretty simple compared to other languages. Take for example the way we express the plural. With only a small number of exceptions, we make plurals by adding a suffix –s to the singular. The pronunciation differs depending on the last sound of the word it attaches to – compare the ‘z’ sound at the end of dogs to the ‘s’ sound at the end of cats, and the ‘iz’ at the end of horses – but it varies in a consistently predictable way, which makes it easy to
Considering that the majority of English speakers learn the language in adulthood, when our brains have lost much of their early plasticity, it’s just as well that some aspects of English grammar are pretty simple compared to other languages. Take for example the way we express the plural. With only a small number of exceptions, we make plurals by adding a suffix –s to the singular. The pronunciation differs depending on the last sound of the word it attaches to – compare the ‘z’ sound at the end of dogs to the ‘s’ sound at the end of cats, and the ‘iz’ at the end of horses – but it varies in a consistently predictable way, which makes it easy to  How did the -s plural overtake these competitors to become so overwhelmingly predominant in English? Partly it was because of changes to the sounds of Old English as it evolved into Middle English. Unstressed vowels in the last syllables of words, which included most of the suffixes which expressed the gender, number and case of nouns, coalesced into a single indistinct vowel known as ‘schwa’ (written <ə>, and pronounced like the ‘uh’ sound at the beginning of annoying). Moreover, final –m came to be pronounced identically to –n. This caused confusion between singulars and plurals: for example, Old English guman ‘to a man’ and gumum ‘to men’ both came to be pronounced as gumən in Middle English. It also caused confusion between two of the most common noun classes, the Old English an-plurals and the a-plurals. As a result they merged into a single class, with -e in the singular and -en in the plural.
How did the -s plural overtake these competitors to become so overwhelmingly predominant in English? Partly it was because of changes to the sounds of Old English as it evolved into Middle English. Unstressed vowels in the last syllables of words, which included most of the suffixes which expressed the gender, number and case of nouns, coalesced into a single indistinct vowel known as ‘schwa’ (written <ə>, and pronounced like the ‘uh’ sound at the beginning of annoying). Moreover, final –m came to be pronounced identically to –n. This caused confusion between singulars and plurals: for example, Old English guman ‘to a man’ and gumum ‘to men’ both came to be pronounced as gumən in Middle English. It also caused confusion between two of the most common noun classes, the Old English an-plurals and the a-plurals. As a result they merged into a single class, with -e in the singular and -en in the plural.




 This was one of the great insights of Ferdinand de Saussure, arguably the father of modern linguistic
This was one of the great insights of Ferdinand de Saussure, arguably the father of modern linguistic